Java语言简介
Java 是由 Sun Microsystems 公司于 1995 年 5 月推出的 Java 面向对象程序设计语言和 Java 平台的总称。由 James Gosling和同事们共同研发,并在 1995 年正式推出。
后来 Sun 公司被 Oracle (甲骨文)公司收购,Java 也随之成为 Oracle 公司的产品。
Java分为三个体系:
- JavaSE(J2SE)(Java 2 Platform Standard Edition,Java平台标准版),更多的时候用于PC客户端,用的不多。
- JavaEE(J2EE)(Java 2 Platform,Enterprise Edition,Java平台企业版),用的很多,主要用于企业级开发(Web、后台等等)。
- JavaME(J2ME)(Java 2 Platform Micro Edition,Java平台微型版),更多的时候用于手机等微型设备端,Nokia时代有人用,现在已经基本没人用了。
跨平台特性
稍微有一些计算机基础知识的同学都知道,不同硬件,它们的区别是很大的,不同的操作系统,区别也很大,毕竟,操作系统是直接工作在硬件之上的。操作系统已经为我们提供了比较一致的操作计算机硬件的接口,但是不同的操作系统因为当初的发明者、后来的开发者,以及不同公司的各种因素等等,导致这些操作系统本身之间的差异就很大,比如要保存一个文件到计算机中,比如要发送一个网络请求,不同的操作系统,差别就非常大。而且在这些操作系统上可以执行的程序的格式本身也不一样。
在计算机软件开发刚刚兴起的最初那些时代,人们想让计算机做一件事情,通常要针对不同的操作系统分别实现一套程序,然后再对这些程序的运行工作情况进行测试验证,才能保证它的工作是符合预期的。这种方式下,工作量比较大、软件开发的成本、效率都不是很理想。所以,后来人们发明了C语言、C++语言等高级语言,这些高级语言基本上屏蔽了不同操作系统之间的这些差异,比如读取一个文件,在C语言中,无论是什么操作系统,都可以通过fread函数来做到。但是,不同的操作系统上的可以执行的程序的格式也是不一样的,所以,虽然写了一份可以在多个操作系统上运行的软件源代码,但是想要让程序可以运行,还需要一个编译的过程中,所谓编译,简单的理解,就是将人类能读懂的程序源代码翻译成机器可以识别的机器码,然后再以相应的操作系统上预先定义好的格式组织起来,让这些操作系统碰到它们的时候可以直接执行。
由上述情况我们了解到,针对C、C++语言,我们可以编写一份能够在各个平台上都可以执行的源代码,然后针对不同的操作系统分别编译出对应的可执行程序,就能实现跨平台,但是这个过程还是比较烦琐的,不同的操作系统上的环境千差万别,要编译出一份正确的没有问题的程序,也是很麻烦的。
所以,Java的开发者,新创造了一种模式,他们开发了一套软件,这套软件作为Java程序和各操作系统之间的中间层而存在,我们姑且称之为执行引擎,这个名叫执行引擎的中间层可以屏蔽不同的操作系统之间的差异,我们这些软件开发人员,只要将源代码写好,然后编译成执行引擎能识别的格式(现在我们称其为字节码)就行了。当然,执行程序的时候,也不是交给操作系统去执行,而是交给这个执行引擎,执行引擎再去完成字节码程序的执行过程。这样,对于我们普通开发者来说,就不必考虑不同的操作系统之间的巨大差异了,这就是Java语言的Write once, run anywhere的理念,即:一次编写,到处运行。
当然了,事实上这仅仅是一个美好的愿望,世上没有完完美的东西,Java语言的这种做法,固然为我们解决了不同操作系统之间的差异问题,但是因为有这个执行引擎的再处理,代码不会直接运行在硬件上,而是有中间层的翻译转换这个过程,所以性能会有损耗,好在现在的计算机运行速度都很快,所以大多数情况下是没问题的。当然也正是因为这个原因,在一些性能要求非常高的场景,人们还是仍然在用C语言和C++语言开发程序,然后编译成可以直接执行的格式,虽然麻烦了点,但是性能有保证啊。
看下面这张图,就更好理解了:
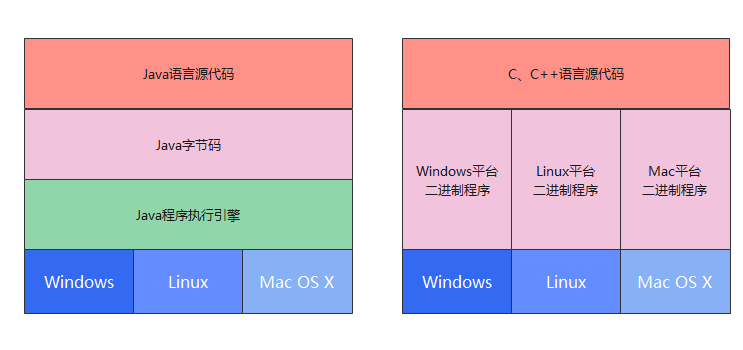
JDK和JRE
JDK是一套软件的总称,指的就是Java语言现在的主要开发商美国的Oracle公司开发的整套Java语言开发工具包(Java Development Kit),有了这个,Java语言就不再是非常简单的一门语言了,它提供了非常丰富的、高性能的、扩展很极强的各种工具包,我们可以使用这些工具包直接开发出自己想要的软件产品出来。
提到JDK,我们就需要顺便说一下JVM,JVM不是一个软件,而是一套基于Java语言做软件开发的规范,在这一套规范之下,各厂商分别实现了一套自己的Java语言开发工具包(还是可以继续简称为JDK了),比如IBM有自己的JDK、Amazon也有自己的JDK、Oracle作为官方正统当然也有自己的JDK。只不过我们平常见的最多的、用的最多的都是OracleJDK,所以就变成提到JDK,就指的是Oracle的JDK了。JDK最早是SUN公司开发的,后来被Oracle公司收购,所以就变成OracleJDK了,市面上常见的JDK有两种:OpenJDK和GraalvmJDK,据业内大神验证,OpenJDK的性能比OracleJDK的性能高20%,而GraalvmJDK的性能又比OpenJDK的性能高20%。当然了,这三套JDK是完全兼容的,你可以随意通用。
OpenJDK和OracleJDK虽然同宗同源,技术特性也很相近,但是它们还有一些区别的,OpenJDK采用GPL v2协议放出,而Oracle JDK则采用JRL放出,此外,OpenJDK只包含基本的JDK实现,而OracleJDK却还包含了其他一些辅助工具(Oracle官方还号称做了许多优化),所以,有人说OpenJDK is an open source version of sun JDK. Oracle JDK is Sun's official JDK.。在2018.9之后,Oracle JDK正式商用(开发不收费,但是运行线上业务收费,所以,开发软件时,使用这两个JDK都可以,但是线上运行时应该使用OpenJDK。尤其有一点要注意,不要去Oracle官网下载他们提供的JDK11,除非你真的弄清楚了它的License并且确定知道自己要怎么做。推荐大家去这里下载:http://jdk.java.net/archive/
JVM就是Java虚拟机(Java Virtual Machine),Java这个编程语言有点特殊,开发出来的程序,编译完之后不是二进制的机器码可以直接让硬件解析执行,而是字节码,这种东西机器不能直接执行,需要在执行的时候再“翻译”一遍。做这个“翻译”的工作的,就是JVM。JVM屏蔽了各操作系统之间的差异,使得上层的Java代码编译出来的字节码可以跨平台运行,实现所谓的“一次编写,到处运行”(Write once, run anywhere)。
说完了JDK,再来说JRE。话说JDK的功能是非常强大的,平时我们开发软件需要用到的东西基本上都有了,但是它有一个问题:当我把软件开发完了之后,运行的时候,我并不需要这么多东西,只需要一个最小支持层就可以了,这个时候,就只需要JRE了,JRE只包含支撑开发好的Java程序运行的组件,不包含开发相关的一些东西。
所以JRE是JDK的一个子集,JVM是JRE的一个子集。

顺便提一下Java语言的版本史,Java最主要的版本是JDK6和JDK8,这是目前市面上见的最多的,JDK6是很多老项目的JDK,如果你去了一家历史悠久的大公司,你会发现他们很多十几年前开发的项目都是基于JDK6的,新兴公司,大都使用JDK8。当然了,截止本文发布,JDK17都已经发布了。这期间还有JDK11、JDK15是LTS版本(长期支持版本)。
开发环境配置
在本章节中我们将为大家介绍如何搭建Java开发环境,不同的操作系统,搭建环境略有不同:
Windows 上安装开发环境
下载JDK
首先我们需要下载 java 开发工具包 JDK,下载地址:https://www.oracle.com/java/technologies/downloads/ ,在下载页面中根据自己的系统选择对应的版本,本文以 Window 64位系统为例:
我们推荐下载zip格式的绿色包,许多网站都建议选择exe格式的安装包运行安装,这里之所以推荐zip格式的绿色包,是因为对于开发经验丰富的人来说,许多时候,要在多个JDK版本之间做一些研究和学习,这就很有必要了。
下载解压之后(当然你也可以下载exe格式的进行安装),要配置环境变量,具体如下:
- 变量名:JAVA_HOME,变量值:
C:\Program Files (x86)\Java\jdk1.8.0_91
- 变量名:CLASSPATH,变量值:
.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
- 变量名:Path,变量值:
%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin
注意 :JAVA_HOME变量的值,要根据你具体安装或解压到哪里了,换成你电脑中的路径,CLASSPATH变量的值是固定的,但是记得它的值最开头有个”.“,不能忽略。Windows上Path环境变量是以英文分号分割的,配置的时候注意和别的已有环境变量以英文分号分开,别连在一起了。
Linux 上安装开发环境
Linux、Mac OS X上其实原理和Windows上差不太多,要注意的是Linux和Mac OS X上Oracle也提供了安装版的JDK,只不过一般没人这么用,都是下载压缩包解压,然后这样配置:
- 变量名:JAVA_HOME,变量值:
/opt/jdk8
- 变量名:CLASSPATH,变量值:
.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- 变量名:PATH,变量值:
$JAVA_HOME/bin:$JAVA_HOME/jre/bin
注意 :JAVA_HOME变量的值,要根据你具体安装或解压到哪里了,换成你电脑中的路径,CLASSPATH变量的值是固定的,但是记得它的值最开头有个”.“,不能忽略。Linux、Mac OS X上PATH环境变量是以英文冒号分割的,配置的时候注意和别的已有环境变量以英文冒号分开,别连在一起了。
安装Eclipse进行Java开发
这是免费开源的IDE(集成开发环境)。
早在2000年前后,当时大家使用Java语言开发大型软件时,用的是位于美国的著名大公司IBM开发的一款名叫Visual Age for Java的IDE开发工具,2001年,IBM又在此基础之上,开发了全新的IDE开发工具,起名叫Eclipse,当时IBM是Java阵营的头部企业(当时Java还属于美国的Sun公司而不是现在的Oracle),微软则正在力推C#以及Java的变种J++,IBM为了在与微软的竞争中胜出,将Eclipse开源,并联合Borland、Red Hat、suse等一些一流厂商,成立了Eclipse基金会,当然了,这个过程不是一帆风顺的,期间经历了很多事情才得以成功,Eclipse基金会成立的时候已经2004年了,但是无论如何,这是一次成功的商业行动,Eclipse作为一家非营业利性质的中立机构,拥有完整的章程、协议、行为准则等。他们将Eclipse工具深化发展,由最初的一个IDE工具最终发展成为了一个开放性的、具备极强的包容性的综合性的开发平台。当然了,在此期间,Java语言的东家也已经由Sun公司转为了Oracle公司,Eclipse又与Oracle就Java语言相关的协议等内容达成了一系列共识,最终成为了现在业界独一无二的优化、强大的软件开发平台。所以,Eclipse不仅仅能用来开发Java程序,还能开发其他编程语言的程序,而且完全胜任大型、超大型的软件系统的开发工作。
安装IDEA进行Java开发
这是一款商业化的、功能非常强大的IDE(集成开发环境),非常好用。
关键字
说Java基础语法之前,我们先说一下关键字。所谓关键字,就是Java语言本身在使用这个单词,然后你在使用Java语言编写代码开发软件的时候,就不能使用这些名字了,因为这些名称被用于特殊用途了。不必记忆,放在这里备忘备查就好了。
Java语言中有以下关键字:
| 关键字 |
含义 |
| abstract |
表明类或者成员方法具有抽象属性 |
| assert |
断言,用来进行程序调试 |
| boolean |
基本数据类型之一,声明布尔类型的关键字 |
| break |
提前跳出一个块 |
| byte |
基本数据类型之一,字节类型 |
| case |
用在switch语句之中,表示其中的一个分支 |
| catch |
用在异常处理中,用来捕捉异常 |
| char |
基本数据类型之一,字符类型 |
| class |
声明一个类 |
| const |
保留关键字,没有具体含义 |
| continue |
回到一个块的开始处 |
| default |
默认,例如,用在switch语句中,表明一个默认的分支。Java8 中也作用于声明接口函数的默认实现 |
| do |
用在do-while循环结构中 |
| double |
基本数据类型之一,双精度浮点数类型 |
| else |
用在条件语句中,表明当条件不成立时的分支 |
| enum |
枚举 |
| extends |
表明一个类型是另一个类型的子类型。对于类,可以是另一个类或者抽象类;对于接口,可以是另一个接口 |
| final |
用来说明最终属性,表明一个类不能派生出子类,或者成员方法不能被覆盖,或者成员域的值不能被改变,用来定义常量 |
| finally |
用于处理异常情况,用来声明一个基本肯定会被执行到的语句块 |
| float |
基本数据类型之一,单精度浮点数类型 |
| for |
一种循环结构的引导词 |
| goto |
保留关键字,没有具体含义 |
| if |
条件语句的引导词 |
| implements |
表明一个类实现了给定的接口 |
| import |
表明要访问指定的类或包 |
| instanceof |
用来测试一个对象是否是指定类型的实例对象 |
| int |
基本数据类型之一,整数类型 |
| interface |
接口 |
| long |
基本数据类型之一,长整数类型 |
| native |
用来声明一个方法是由与计算机相关的语言(如C/C++/FORTRAN语言)实现的 |
| new |
用来创建新实例对象 |
| package |
包 |
| private |
一种访问控制方式:私用模式 |
| protected |
一种访问控制方式:保护模式 |
| public |
一种访问控制方式:共用模式 |
| return |
从成员方法中返回数据 |
| short |
基本数据类型之一,短整数类型 |
| static |
表明具有静态属性 |
| strictfp |
用来声明FP_strict(单精度或双精度浮点数)表达式遵循IEEE 754算术规范 |
| super |
表明当前对象的父类型的引用或者父类型的构造方法 |
| switch |
分支语句结构的引导词 |
| synchronized |
表明一段代码需要同步执行 |
| this |
指向当前实例对象的引用 |
| throw |
抛出一个异常 |
| throws |
声明在当前定义的成员方法中所有需要抛出的异常 |
| transient |
声明不用序列化的成员域 |
| try |
尝试一个可能抛出异常的程序块 |
| void |
声明当前成员方法没有返回值 |
| volatile |
表明两个或者多个变量必须同步地发生变化 |
| while |
用在循环结构中 |
数据类型
基础数据类型:
| 类型 |
字长(字节) |
包装类型 |
| int |
4 |
Integer |
| short |
4 |
Short |
| byte |
1 |
Byte |
| long |
8 |
Long |
| double |
8 |
Double |
| float |
4 |
Float |
| boolean |
1 |
Boolean |
| void |
- |
Void |
Java的每一种基本数据类型,都应对一种包装类型,如我们最常见的基本类型int,它对应的包装类型是Integer,那么这个包装类型是用来做什么的呢?事实上,这个包装类型,是专门用来处理“面向对象编程”的。不好理解?不要紧,我们换个说法:现在要保存一个整数列表,我们需要使用List<Integer>而不能是List<int>,为什么?因为List中的内容必须是一个个的对象,而不是数字,是的,你没看错,如果你在Java中写了一个int类型的数字10,它不是个对象,所以它不能放到List中去。而Integer类型的数字10就能放到List中去,因为它是个对象。最后再来究极一问:为什么int类型的一个数字不是对象而Integer类型的一个数字就是对象了呢?答案是:Java就是这么设计的,为什么这么设计呢?为了性能,int类型的数据,都是在栈上甚至是寄存器上运行,很快,而Integer类型的对象,必须在堆上,慢啊。既想要性能,又想要面向对象,所以,就这么人格分裂咯。
变量的定义和使用
这个太简单了,几乎没什么可说的,看代码:
int a = 10;
double b = 3.14;
String s = "name";
只有一点需要注意:基础类型和包装类型是不一样的,前面已经讲过了。另外,变量定义的时候,名称不要胡起,比如你生个孩子,起个名字叫混账,这怎么能行呢😂?起名字要“正常”一点,比如学生,就叫student,比如评分,就叫score。见名知义,是最好的😀。
我们还可以定义一些稍微复杂一点的变量:
int[] numbers = new int[]{1, 2, 3};
List<String> charactors = new ArrayList<>();
Map<String, String> students = new HashMap<>();
第一个是定义了一个数组,第二个是定义了一个列表,第三个是定义了一个Map(键-值映射)。这些都是JDK为我们提供的能力,可以很方便的保存各种复杂的业务数据。需要注意的是:像列表、Map可以在定义的时候保存数据,也可以定义好了之后再保存数据,这些我们以后会接触到。
知道了变量的定义,就要掌握运算符。请看后续章节,让我们继续学习运算符。
运算符
算术运算符
算术运算符的结果类型不变,原来是什么类型,结果仍然是什么类型:
| 操作符 |
描述 |
例子 |
| + |
加法,两数相加 |
a + b |
| - |
减法,两数相减 |
a - b |
| * |
乘法,两数相乘 |
a * b |
| / |
除法,两数相除 |
a / b |
| % |
取余,左数除以右数,取余 |
a % b |
| ++ |
自增,让变量的值增加1 |
a++ |
| -- |
自减,让变量的值减少1 |
a-- |
这里会有一些隐式的类型转换,原则:小类型向大类型自动转型(当然也可以手动强制转换)。
关系运符符
关系运算符的计算结果是一个boolean型的结果:
| 操作符 |
描述 |
例子 |
| == |
检查两值是否相等,相等得true,其他情况得false |
a == b |
| != |
检查两值是否不相等,不相等得true,其他情况得false |
a != b |
| > |
检查左侧是否大于右侧,大于得true,其他情况得false |
a > b |
| < |
检查左侧是否小于右侧,小于得true,其他情况得false |
a < b |
= | 检查左侧是否大于等于右侧,大于或等于得true,其他情况得false | a >= b
<= | 检查左侧是否小于等于右侧,小于或等于得true,其他情况得false | a <= b
逻辑运算符
逻辑运算符的计算结果是一个boolean类型的结果:
| 操作符 |
描述 |
例子 |
| && |
检查两侧值是否都为true,满足条件为true,其他情况为false |
a && b |
| || |
检查两侧值是否有一个为true,满足条件为true,其他情况为false |
a || b |
| ! |
仅右侧有值,右侧是true是得false,右侧是false时得true,即:取反 |
!a |
运算符优先级
运算符优先级原则:
- 算术运算符优先级高于关系运算符
- 关系运算符优先级高于逻辑运算符
- 可以使用括号手动改变运算顺序,这很有用,既便于理解,又能很好的控制计算顺序
Java运算符优先级
这张表其实不用记忆,放在这里只是备查
| 优先级 |
描述 |
运算符 |
| 1 |
括号 |
[]、() |
| 2 |
后缀式一元运算符 |
i++、i-- |
| 3 |
一元运算符 |
++i、--i、+a、-a、~a、!a |
| 4 |
乘、除、取余 |
*、/、% |
| 5 |
加减 |
+、- |
| 6 |
移位 |
<<、>>、>>> |
| 7 |
关系大小运算和实例判断 |
<、>、<=、>=、instanceof |
| 8 |
相等关系运算 |
==、!= |
| 9 |
按位与 |
& |
| 10 |
按位异或 |
^ |
| 11 |
按位或 |
|
| 12 |
与 |
&& |
| 13 |
或 |
|
| 14 |
三元运算符 |
?: |
| 15 |
带赋值功能的运算符 |
= += -= *= /= %= &= ^= |
在上述的Java编程语言的运算符优先级表格中,越靠近表的顶部,其优先级就越高。在遇到相对较低优先级的运算符之前,对具有较高优先级的运算符进行求值。同一行的运算符具有相等的优先级。当具有同等优先级的运算符出现在同一表达式中时,必须首先控制一个规则。除赋值运算符外,所有二元运算符从左到右进行求值(左结合性);赋值运算符从右至左进行运算(即:将右边的值赋给左边)。
流程控制
分支判断
这个也很简单,示例代码:
int score = 100;
if (a > 60) {
System.out.println("万岁")
} else {
System.out.println("受罪");
}
是不是很简单?这段代码中的System.out.println是JDK提供的一个类和方法,用于在屏幕上输出内容,眼下你会用就行了,细节以后再学习研究。
后面的else不是必须的,换句话说,我可以实现一个需求:某个条件符合时,做某个,不符合时,什么也不做。如下所示:
int score = 100;
if (a > 60) {
System.out.println("万岁")
}
但是要注意:以上述代码为例,万一有人弄进来了一个200分呢?或者这个时候有个表示年龄的变量,它的值是已经是500了呢?我们知道人是不可能活500年的(我真的还想再活500年,那只会在歌曲中出现哦~),这个时候,其实它就有个BUG,代码在某些时候,运行的结果就是错的,所以,要改:
int score = 100;
if (a > 100) {
System.out.println("这是什么鬼,我不认识");
} else if (a > 60) {
System.out.println("万岁");
} else {
System.out.println("受罪");
}
这个代码逻辑就没问题了,同样的,处理人的年龄的时候,也应该是这样的:
int age = 100;
if (a > 120) {
System.out.println("史无前例的高寿,有福啊!");
} else if (a > 100) {
System.out.println("高寿,有福啊!");
} else if (a > 80) {
System.out.println("老寿星,您好!");
} else if (a > 60) {
System.out.println("老爷爷好!");
} else if (a > 40) {
System.out.println("叔叔好!")
} else if (a > 20) {
System.out.println("哥们好!")
} else if (a > 3) {
System.out.println("小朋友你好!")
} else {
System.out.println("去吃奶吧。");
}
对于固定的、又有很多个值的情况,写那么多的if…else明显有点难受,Java为我们提供了switch,也很方便,示例:
char ch = 'a';
switch (ch) {
case 'a':
System.out.println(1);
break;
case 'b':
System.out.println(2);
break;
case 'c':
System.out.println(3);
break;
default:
System.out.println(0);
break;
}
是不是简洁易读多了?需要注意的是,break语句是必须的,如果没有,会导致所谓的switch Fall-through,当然,特殊情况下也是有用的:
int a = 1;
switch (a) {
case 1:
case 2:
case 3:
System.out.println("top3");
case 4:
case 5:
System.out.println("top5");
break;
default:
System.out.println("not");
}
这段代码的逻辑有点特殊,我帮你要梳理一下:如果a的值是1、2、3,那么就是top3,如果a的值是1、2、3、4、5,那就是top5,如果a的值是4、5,那么它是top5但不是top3,这些情况都不是,那就not。
如果switch…case语句中,case后面的内容是字符串,只能在JDK7及以上使用,更老的项目上是不支持的:
String s = "a";
switch (ch) {
case "a":
System.out.println("A");
break;
case "b":
System.out.println("B");
break;
case "c":
System.out.println("C");
break;
default:
System.out.println("0");
break;
}
fall through的字面意义是落空、告吹、破灭。但是在这里明显感觉有点词不达义。大家将就着理解吧,目前网上没找到权威的解释,都处于一种“代码就是这样的,执行时的行为是那样的,你自己领悟吧”的状态中。
循环
Java中主要有三种循环:
- for循环
- while循环
- do…while循环
for循环
Java中的for循环通常用于知道循环次数的情况,如:
for (int i = 0; i < 10; i ++) {
System.out.println(i);
}
逻辑很简单:将0到9打印出来。
for循环还有另外一种用法:遍历数据,这种用法叫增强for循环,如下所示:
int[] numbers = new int[]{1, 2, 3, 4, 5};
for (int number : numbers) {
System.out.println(number);
}
这是遍历numbers这个数组,数组内容变化之后,for循环不必修改,仍然能将数组的所有内容都打印出来,很方便。但是这里要注意:numbers不能是null,否则会抛出NullPointException,所以循环之前要判断一下。具体什么是异常,我们以后会再学到。
👉Tips:这种循环又称为增强for循环,或foreach循环,它是JDK5中才出现的。
while循环
语法:
while( 逻辑表达式 ) {
//循环内容
}
只要逻辑表达式的值为true,就会一直循环执行下去,通常用于根据唯一条件进行循环,如:
int r = 0;
while (r >= 100) {
r = getDownloadPercent();
System.out.printf("Downloading %d", r)
}
这段代码的逻辑很简单:getDownloadPercent是一个模拟方法,它获得文件下载的进度,当下载进度是100的时候,就退出循环了,循环条件也可以写成r == 100,但是在某些情况下,有可能出现超出100的时候,那就死循环了,所以为了确保万无一失,我们写成r >= 100,这就是代码的健壮性了。
do…while循环
do…while循环通常用于不知道循环次数,只能在某种情况下结束,这种情况要注意,一个不小心就死循环了,所以写这种代码的时候,逻辑要理清楚。另外,do…while还有一个好处,它不执行判断条件,直接开始执行这个do…while逻辑块中的代码,执行完了再判断是否进行下一次循环。示例:
// 用户手机号列表
List<String> mobileList = null;
int page = 1, pageSize = 10;
do {
mobileList = queryUserMobilesByPage(page, pageSize);
page++;
} while (mobileList != null && !mobileList.isEmpty());
这是一个非常典型的示例应用:先定义一个保存手机号的列表,然后定义页码和页大小,然后按指定的页大小逐页查询所有手机号。如果找不到了,就结束循环。
类和实例
关于类
什么是类?类就是对同一种东西的抽象,抽象层次不同,形成的结果差异也很大。比如:人,这个抽象级别就非常高,可以概括我们所有人,比如学生,它的抽象级别就低多了,限定了年龄、职业等信息,再比如:男学生,就在学生的基础上更趋向于具体:在学生的基础上,限定了性别。所以,我们可以通俗的理解:抽象级别越高,能概括的范围越广,抽象级别越低,越趋近于具体的某个事物。接续前面的描述:某某学校的、学号为某某某、年龄为某岁的男学生。这就到了这个具体的学生了,它就不是抽象,而是具体。
到此,相信大家都已经理解了什么是类了,类就是对同一种东西的抽象。
在Java中,定义一个类非常简单:
class People {
}
这是个类,但是它是空的,里面什么都没有。
针对类,我们还可以添加一些字段用于表述它们拥有哪些特性,再添加一些方法用于表述它们能做些什么:
class People {
String name;
int age;
String getName() {
return name;
}
void sayHello() {
System.out.println("你好");
}
}
在这个类中,它拥有两个字段:name和age,用于表述这个类具有姓名和年龄,此外它还拥有两个方法:getName、sayHello,在Java中,定义变量的时候,首字母小写,其他单词的首字母大写,定义类的时候,每个字母都大写,这叫驼峰命名法。顺便来几个示例:
- 变量名:name、age、address、mobile
- 类名:User、Student、PublishQueue、MyStack、HttpClient
> 通常情况下,一个java代码文件中放一个类,然后让该文件名称和类名称完全一致,当然也可以放多个,但是这涉及到代码包和访问权限的问题,我们后面再说。
对于getName这种获得这个类的成员,Java中有一个约定俗成的做法:方法名称是由字段名演化而来的,具体的演化规则是,字段名称首字母大家,然后前面加上get,其余保持不变,这是获取字段属性,所以有人称之为获取器,相信聪明如你,肯定想到了,既然能获得一个类的字段,那么能不能设置一个类的字段呢?答案当然是可以的,如下所示:
class People {
String name;
int age;
String getName() {
return this.name;
}
void setName(String name) {
this.name = name;
}
int getAge() {
return age;
}
void setAge(int age) {
this.age = age;
}
}
看,其实很简单吧,getter是获取器,又称访问器,用于获得字段的值,setter是设置器,用于修改字段的值。
此外,在定义类的时候,我们还可以在类的内部再定义一个类(也就是嵌套),这个叫内部类:
class Student {
String name;
int age;
class Address {
String province;
String city;
String county;
}
}
理论上我们还可以在方法中定义类,但是基本上没人这么用,我们就忽略吧。
关于类的定义,相信你已经看到上面的一些代码中,方法中有个this,它代表该类的一个实例,那么什么是实例?这个this又是哪个实例呢?
关于实例
实例,就是某个具体的事物,比如前一节中所描述的某某学校的、学号为某某某、年龄为某岁的男学生,这就是很具体的一个学生,而不是很简单很抽象地说人,因为这样太笼统了,很难在许多业务场景中直接使用。
所以,实例,是对类的具体定义。那么,当我们定义了类之后,我们就能定义实例了。定义类的时候,我们要明确它的一些具体属性,比如学生,就是一个类,它的所在学校、学号、年龄等属性,任何学生都有这些属性,但是具体到各个学生,他们的很多信息是不一样的,所以,类型是共性,实例是个案。
在Java中,定义一个类的实例也很简单:
People p = new People();
我们接着往下看:
People p1 = new People();
System.out.println(p1.getName());
People p2 = new People();
System.out.println(p2.getAge());
这里,我们针对类People,创建了两个实例:p1和p2,那么,当执行p1.getName()方法时,this就是p1,当执行p2.getAge()方法时,this就是p2。现在理解了吧。
这里要强调一个事情:类有字段,但没有字段值,只有实例才有字段值。为什么是这样的?你想想:人的年龄是20岁,这话有毛病没有?你突然听到这一句话,不蒙么?但是我要是说:张三这个学生年龄是20岁。这话就一点问题都没有。类是一个抽象的东西,它不拥有具体的字段值,只有具体的某个事物,才拥有具体的某些特性,所以,再强调一遍:通常情况下,类只有字段,实例才有字段值。
但是也有例外,某些时候,某个类的所有实例,都拥有一个相同的属性,在它的所有实例中写一遍,似乎也比较麻烦,而且也不太合理,那么此时我们可以把这个属性放到类中,变成类的一个字段,这样这个类的所有实例就可以直接使用了,如下所示:
class People {
String name;
int age;
static String color = "黄色";
}
所有人的皮肤都是黄色的,就统一放到类中去(用static关键字标表这种用法),那么这个类的所有实例都可以使用了,省的到处写一遍,唔…没毛病。
People p = new People();
System.out.println(p.color);
当一个类中有static型的字段时,我们除了通过实例访问它,还可以通过类名直接访问它,如下所示:
System.out.println(People.color);
这个很好理解,color是People这个类的,不是某个实例的,所以在没有实例的情况下,我们可以直接使用它。
还有,在一个类中再定义内部类的时候,也可以指定该内部类是否为static,同样的道理:如果该内部类是static的,那么我们可以直接在外部类上使用,如果该内部类不是static的,当然就不能在外部类上直接使用了,这个时候它是属于外部类的实例的,有了外部类的实例,才能通过实例使用该内部类。
class Student {
String name;
int age;
static class Address {
String province;
String city;
String county;
}
}
类的继承机制与接口
前面我们已经描述清楚了什么是类,但是我们同时也发现,学生这个类型,它有一些东西,其实是和人这种类是通用的,所以,我们可以进一步进行归纳整理,先定义人这种类型,再定义学生这种类型,然后让学生这种类型继承人这种类型,那么就感觉简单明了多了。类似地,我们用一张图表示这样一种抽象逻辑关系:
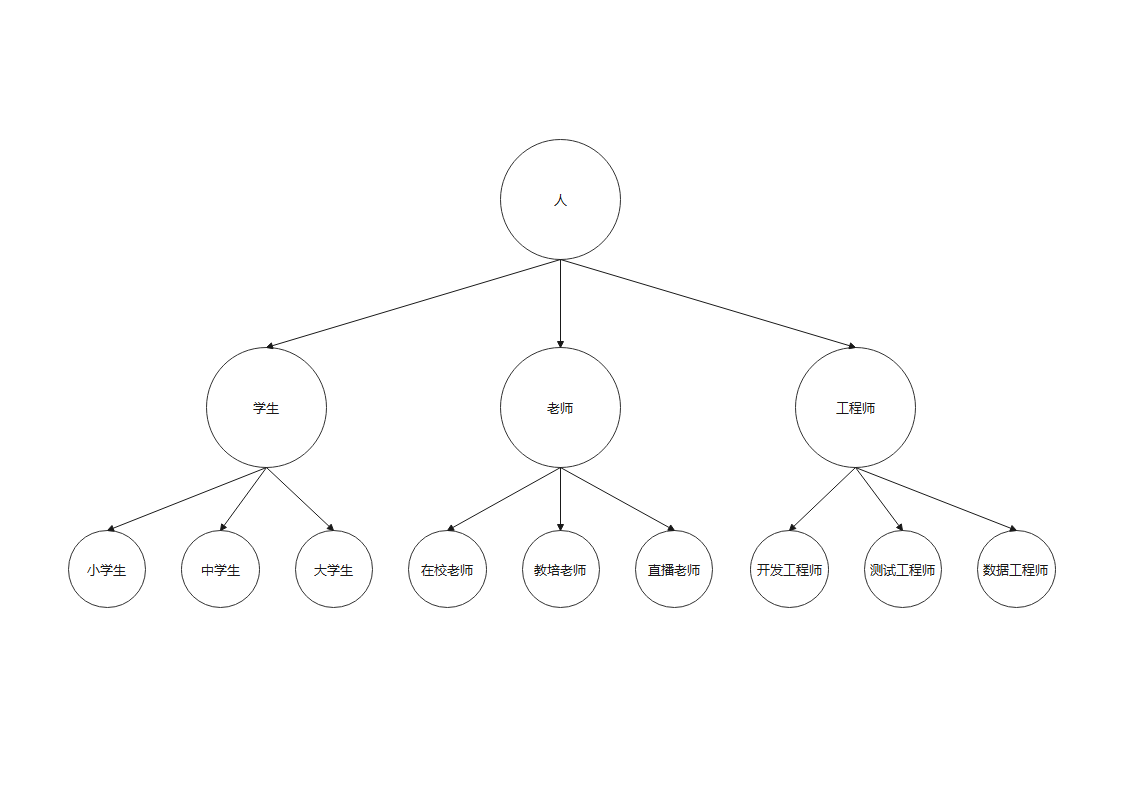
那么,接口又是什么呢?接口其实是对类的行为的抽象定义,比如人的吃饭行为、动物的奔跑行为,定义了之后,就可以让某个类拥有这些行为,当一个类拥有一个接口的所有行为时,我们称该类实现了该接口。同时,这些行为还可以给其他类使用,这叫复用,能够让同一种东西(比如移动这个行为)在多个地方使用,这对于简化软件开发具有重要意义,在以后的具体的开发中,我们会接触到更多这方面的信息。
了解了这些信息,那么具体写代码的时候怎么做呢?其实很简单的,往下看。
在Java中,让某个类继承另外一个类的写法是这样的,先定义父类:
class People {
String name;
int age;
}
再定义学生子类,并让该子类继承父类:
class Student extends People {
String studentId;
}
extends是关键字,表明子类Student继承了People类,而且子类拥有父类的name和age两个属性,再加上自己本身拥有的studentId属性,它就拥有三个属性了。
我们还可以再定义一个老师类:
class Teacher extends People {
List<String> lessonList;
}
子类Teacher和Student类一样,也拥有三个属性:name、age、lessonList。
需要注意的是:在Java中,只能实现单继承,不支持多继承,也就是说:b可以继承a,然后c也可以继承a,此时不能再定义一个d同时继承b和c,这是不可以的,有的同学可能熟悉C++,知道能这么定义,Java不可以。
在Java中,定义一个接口也很简单:
interface Moveable {
double distance();
}
现在,定义一个类,让这个类实现这个接口:
class Dog implements Moveable {
@Override
double distance() {
System.out.println("小狗在奔跑");
return 10.123;
}
}
这个定义表明:我们有一个描述移动的接口,同时定义了一个狗类,狗能移动,于是它实现了Moveable这个接口(通过implements关键字),代码中的@Override就是用于表明这个distance方法是来自接口的,它是可选的,可以不写,但是为了便于代码一目了然易于理解,我们还是写上比较好。
我们可以通过上述例子看到,类是包含各种字段(代表数据)和方法(代表行为)的,接口仅仅是声明方法(行为)的。可是有的时候,我们还有一个需求:我定义一个类,规定一些行为,但是又有部分行为只声明不实现,让别人继承它去自己做,兼具灵活性和便捷性。这个时候,就需要通过abstract声明抽象类,如下所示:
abstract class AbstractRequest {
String url;
String param;
abstract public String doRequest();
public String buildParam(Map<String, String> param) {
for (String key : param.keySet()) {
this.param += String.format("%s=%s?", key, map.get(key));
}
}
}
在上述代码中,我们声明了一个发送网络请求的类,同时我们写了一个buildParam方法,将一个Map转化成为字符串,无论是GET还是POST还是其他请求,URL上需要参数的时候,我们都可以调用buildParam方法,但是GET、POST等请求的具体执行逻辑是不一样的,而且我们也不知道使用我们这个类的人他什么时候用什么请求,所以这个时候,我们声明了一个抽象方法doRequest(),它只有声明没有实现,目的就是让使用这个类的人去继承这个类,然后实现这个方法。你可以简单地理解:我声明了一个模板,基础的东西我都搞好了,具体怎么发请求,你自己去弄,弄好了就可以直接用了。注意: 如果一个类中有至少一个方法被声明为抽象方法了,那么该类就必须是抽象类。
一个大型、超大型的软件,其中的类继承关系一般是比较复杂的,这也是通常情况下这样的软件会有很多个人一起开发,最后进行系统集成的原因所在,我们再看看JDK中最常用的ArrayList这个类的继承关系如下图所示:

带I标识的是接口,带双竖线的C的是抽象类,带C标识的是类
static块
之所以将这个static块单列一节讲,是因为它比较特殊,分两方面说。
第一:我们前面已经说了,如果一个内部类是static的,那么外部类可以直接使用它,因为它和外部类是绑定在一起的,如果一个内部类不是static的,那么外部类不能直接使用它,要么将内部类实例化之后使用它的实例,要么外部类实例化之后,通过外部类的实例访问内部类。
第二:一个类的static块,是在JVM进程启动的时候执行的,而不是实例定义的时候(也就是new这个类的实例的时候)执行的,有下面的示例代码:
public class Student {
static {
System.out.println("Student static块");
}
static class Address {
static {
System.out.println("Student.Address static块");
}
}
public static void main(String[] args) {
System.out.println("Student.main 方法 1");
System.out.println(new Student.Address());
System.out.println("Student.main 方法 2");
}
}
并且,内部类的static静态块只会在它被实例化的时候执行。
如果你有Java基础了,可以运行上述代码看看,如果没有,也没关系,我们后面学了怎么运行代码之后,再回过头来运行它也是可以的。
代码包和访问权限
掌握了上面这些知识之后,我们就可以写很多个类、实例、变量等等,再定义一些数据结构,用于表示我们的业务系统中的一些东西了,进而把需求实现出来,做出一套软件系统,但是,这里面有一个非常常见的问题:我定义的某个东西,想让所有人都能访问,或者,我定义的某个东西,我只准备自己用,不想让其他人使用。这个要怎么做到呢?这就涉及到代码包和访问权限了。
事实上,代码包不仅仅是用来控制权限的,它还是用来组织代码的,当一个软件中代码很多的时候,我们肯定要分门别类把它们组织好,否则乱成一团,最后就太复杂了,就搞不定了。
代码包
代码包,其实就是把担负相同职能的代码放在一起,比如做数据计算的多个类放在一个文件夹中,做网络请求的多个类放在一个文件夹中。于是就有类似于下面这样的结构:
.
├── src
│ ├── math
│ ├── network
│ ├── file
是不是看上去简洁明了了许多?但是,即使有这样的管理思路,仍然要解决每个人都单独搞一套的问题,只有大家都统一使用一致的代码管理策略,才能防止各个地方的代码千差万别,因为代码是为了解决大家需求上的实际问题的,所以这种千差万别只会让软件开发成本上升,不利于软件产品快速交付。所以,我们有一套统一的约定,所有人都按这个方式组织自己的代码,如下所示:
.
├── src
│ ├── main
│ │ ├── java
│ │ ├── ├── domain
│ │ ├── resources
│ ├── test
│ │ ├── java
│ │ ├── ├── domain
│ │ ├── resources
│ target
针对上述结构,我们很有必要逐项解释一下:
- . 指的是项目根目录,这个很好理解,你有可能会开发多个软件,每个软件的代码都放在自己的某个目录中,这个目录就是该软件代码的项目根目录
- src 指的是源代码目录,这个目录中放的都是源代码
- main 这里放的是软件产品的代码,以及软件运行时所需的资源文件和配置文件
- java 这里放的是软件产品的真正代码,一套软件包含很多东西,真正的软件代码放在这里
- resources 这里放的是软件产品的资源文件和配置文件,一个软件要运行起来,需要很多资源和配置(比如数据库的IP、端口、账号和密码等),并且有可能不同的环境不一样(比如测试环境和生产环境以及演示环境的账号密码是不一样的),它们放在这里
- src 这里放的是软件产品的测试代码、以及运行测试代码所需的资源文件和配置文件
- java 这里放的是软件产品的测试代码,测试代码是用于测试验证软件的真正代码是否能够正常、正确地运行的,由于每个开发者对需求的理解不同、开发人员的水平不同,或者团队之间协作存在问题,都会导致软件的代码可能会出现问题,这个时候我们就需要编写测试代码,对软件真正的代码的运行情况进行测试验证,确保它们的运行行为、运行结果是符合预期的,只有这样的产品才是有用的产品,才能交付给客户
- resources 这里放的是运行软件产品的测试代码时所需的资源文件和配置文件,一个软件的测试代码要运行起来,需要很多资源和配置(比如数据库的IP、端口、账号和密码等),并且有可能不同的环境不一样(比如测试环境和生产环境以及演示环境的账号密码是不一样的),可以将它们放在这里
- target 这里放的是编译之后的字节码文件,以及将很多字节码文件、资源等各类支持、配置文件一起打包生成的jar文件的war文件
- domain 在上述代码包结构中,main/java和test/java下都有一个domain,它其实是个域名的含义,但通常会倒着写。什么意思呢?比如你们公司的域名或者你正在开发的软件产品使用的域名是a.com,那么这个domain就是com.a,此时真正的软件代码自然是放在目录src/main/java/com/a中的,同样的,测试代码也是放在目录src/test/java/com/a中的。
当我们将自己的代码文件按上述结构放到相应的目录中的时候,我们就完成了对代码文件的组织管理的第一步,还有最重要的第二步,就是在代码文件中声明该代码文件的包名,例如,我们在src/main/java/com/a目录下创建了一个Hello.java文件,那么就要在这个代码文件的开头这样写:package com.a;,这表示这个Hello.java中的类都是包com.a下的。
访问权限
回到我们之前曾经提到过的一个问题:当我将自己的代码分门别类的组织好了之后,有一个需求就出现了:某些代码我不想让别人访问,某些代码我想让别人访问,某些代码我想让相同代码包中的人访问而其他人不能访问,这就要使用访问权限来解决了,Java中提供了三个关键字public、private、protected,用于解决这个问题。具体约定如下:
| 权限限定关键字 |
类内部 |
本包 |
子类 |
外部包 |
| public |
√ |
√ |
√ |
√ |
| protected |
√ |
√ |
√ |
× |
| private |
√ |
√ |
× |
× |
| default |
√ |
× |
× |
× |
我们对上面这个解释一下:
- public关键字用于修饰一个类、类中的内部类、类中的字段,此时任何人都能访问它
- protected关键字用于修饰类中的字段成员,以及类中的内部类,此时只有本包中的其他类和当前类的子类能访问它
- private关键字用于修饰类中的字段成员、以及类中的内部类,此时只有本包可以访问它
- default并不是说default关键字,而是指当我们写了一个类、字段、内部类时什么都没有加的时候(既没有public、也没有protected、也没有private)的默认值,此时只有该类能访问它
- 总体上,在一个类内部,无论用什么修饰,都能访问
- 最后再加一个约定:一个后缀为.java的源代码文件中,用public修饰的类,有且只能有一个
下面写几个例子看一看:
一个单独的公开类文件:
// Hello.java
public class Hello {
}
一个单独的公开类文件,内部有字段和内部类:
// Hello.java
public class Hello {
public String name = "hello";
private int order;
protected List<String> elements;
public class Greet {
}
}
在一个代码包com.example.io中,有多个类:
// 文件:src/main/java/com/example/io/File.java
package com.example.io;
public class File {
private String name;
private String size;
}
// 文件:src/main/java/com/example/io/FileOperator.java
package com.example.io;
public class FileOperator {
private int result;
public create(File file) {
// 创建文件的实现代码
}
public delete(File file) {
// 删除文件的实现代码
}
}
最后再说一个业界通行的做法:一般情况下类中定义给实例用的字段成员,通常都是private的,顶多是proctected,不会是public,只有放在类上直接使用的字段,才会是public,然后对实例上要用的各字段,添加getter和setter方法。这么做的好处是:如果这里的代码逻辑有变动,调用这段代码的人可以不必修改。所以,我们上述的各测试代码,都省略了getter和setter方法。
> 事实上,当前阶段,许多人都发现了这个问题:假设一个类中有20个字段,那么它就有40个方法,代码很长很冗余,可是又不能没有,很麻烦,所以就有业界的大神搞了一个叫lombok的东西来简化操作,这个我们以后会涉及,今天了解一下就可以了。
注意: 使用package关键字声明代码包的语句必须位于文件开关(注释除外)。
最简单完整的程序
现在,所有基础的东西都讲的差不多了,我们可以写一个稍微完整一点的示例了。按照业界通例,最简单最完整的程序就是Hello World:
package cn.ms11;
// MyHelloWorld.java
public class MyHelloWorld {
public static void main(String[] args) {
System.out.println("MyHelloWorld.main 方法");
}
}
这段程序中的几个知识要点:
- 包声明,这个之前已经说过了
- 类,一个文件中有且仅有一个public访问权限的类,文件名称和类名称一致,这个之前也说过了,有main方法的类必须是public访问权限
- main方法,这是Java程序的入口,计算机从此处开始执行代码,main方法退出了,程序也就结束了,main方法的声明必须是这样的,不能修改
- main方法中的args,是执行Java程序的时候传进来的命令行参数
Java对象和OOP
之所以将Java中的对象单独拿出来说,是因为这里有一些我们后面会多次接触到的一些共性知识,所以有必要强调一下。
面向对象编程OOP
Java是一门面向对象的编程语言,它的代码中,只有类,没有单独的函数,每个类中,又有许多成员,如此完成对现实世界的抽象和描述,因此有人称其最最激进的面向对象编程(Object Oriented Programming,OOP)。因此,在这里我们有必要再简单了解一下什么是面向对象编程。
面向对象编程有三大特性:
- 继承,继承,就是父类子类的继承关系,又称基类和派生类,这个前面我们已经介绍过了。
- 封装,封装的基本思想是对访问开放、对修改关闭,并且坚持最小开放原则。对访问开放、对修改关闭,指的就是getter和setter,外部访问经过统一出入口进行管理,可以避免内部过多的细节暴露,最小开放原则,就是指能不开放的,就不开放,必须要开放的,才开放。比如我们用一个类完成了对一种现实世界中的事物的抽象,它有很多字段用于描述事物的属性和状态,还有很多方法用于描述事物的行为和动作,这种情况下,就没有必要全部开放出去,需要哪个开放那个即可。
- 多态,多态是指父类有多个子类的时候,代码可以在运行期间动态的决定执行哪个类,而不是编写代码的时候就已经写死了固定了。
关于多态,因为实践中应用很多,我们有必要举例子再做一个说明:
abstract class Father {
abstract void sayHello();
}
class SonA {
void sayHello() {
System.out.println("SonA sayHello");
}
}
class SonB {
void sayHello() {
System.out.println("SonB sayHello");
}
}
测试代码:
class PolymorphicTest {
public static void main(String[] args) throws Exception {
Father father = null;
Scanner sc = new Scanner(System.in);
String son = sc.nextLine();
if (son.equals("a")) {
father = new SonA();
} else if (son.equals("b")) {
father = new SonB();
} else {
throw Exception("无法识别的输入");
}
father.sayHello();
}
}
针对这段代码,在开发期间,我们是不知道运行时的状态的,只有运行时,才能知道用户输入的是什么,然后决定是执行SonA的方法、SonB的方法,还是无法处理时抛出异常。
我们再来解释一下面向对象编程中非常常见的重载、重写、覆盖的概念。
- 如果父类存在该方法,子类也存在同样的方法,我们称之为重写(Override),即:子类重写了父类的方法
- 如果一个类中存在两个相同名称的方法,我们称之为重载(Overload),此时两个方法的参数类型和数量不能完全一样,否则代码就区分不出来了
- 子类重写了父类的方法,我们就称父类的方法被覆盖了
对象与内存布局
我们先看JVM的内存模型,来张从网上找到的图:

解释这张图之前,我们先说说什么是线程,线程是一个非常复杂的东西,我们后面还有专题学习,这里先简单说一说。线程就是计算机的CPU的一个执行单元,每当我们想让计算机完成一项任务的时候,我们就可以将这些任务的若干个步骤放在一起,打包成一个执行单元,统一交给CPU去执行,这就是线程。很明显,CPU要承接很多个任务,那就会有很多个线程,问题是,对于单核CPU而言,它其实在一个时刻只能执行一个任务,所以,CPU会给每个线程分配一点点时间(称为时间片),这一点点时间过了之后,再执行下一个线程,然后再照此法执行后面等待的其他线程,如果完成所有线程的调度,这个时间是非常短的,所以给使用计算机的人的感觉就是CPU同时完成了很多任务(比如边下载文件边播放音乐,我们既不会看到下载中断也不会发现音乐播放中断)。对于多核CPU而言,优势是各个内核可以分别开始执行自己的线程队列中的线程,感觉性能一下子就提升了很多,但是新的问题出现了,多个线程很多时候会竞争一个资源,比如多个线程同时往磁盘中写入文件,而磁盘只有一个,磁盘控制器也没有一个,磁盘的缓存也只有一个,在某些情况下,还会出现线程B必须等待线程A完成之后,从线程A得到某个结果再做某事,这些都涉及到线程同步和线程锁的问题。所以,线程的调度是一件非常复杂的事情,我们以后再详细学习。
初步了解了什么是线程之后,我们就说说这个JVM内存模型,我们往简单了解释:
- Java程序启动,创建一个主线程,主线程给自己开辟一块内存空间,用于保存线程运行期间的数据,这块内存称为栈,栈的空间一般很小,1MB到2MB
- 线程在运行的过程中,又创建了其他线程,称为子线程,这些子线程和主线程没有任何区别,同样需要自己的线程栈。由此可知,每个线程都有自己的线程栈
- 线程在执行某个实例的方法时,会开辟一块内存空间,用于保存该方法执行期间的数据(比如方法中的局部变量、返回值等),这个称为方法栈
- 某个实例的方法执行完毕返回了,刚才的方法栈就要释放,内存空间回收
上面这个过程,就是Java中线程执行代码的过程,但是这里有个问题要统一回答:线程栈是很小的,一些很大的对象(比如一个列表,里面有10万个元素),很明显在栈上放不下,所以Java又在整个JVM进程启动的时候,在系统内存中专门申请了一块很大的内存空间,用来存放这些大对象,这就是堆,然后代码在运行时,栈上用变量保存堆中的大对象的地址,通过变量的值就可以找到堆中的大对象了。现在,它们的特点很明了了:
- 栈,运行时动态创建、动态回收,很小,所以创建和回收都很快,里面主要存放的是局部变量(当然,还有其他一些东西)和一些基础类型(int、boolean等)的数据,栈是线程内部专用的
- 堆,JVM启动的时候创建,很大,所以创建和回收相对栈来说是慢一些的,里面主要存放的是各种对象,尤其是比较大的对象,堆是所有线程共享的(所以在某些情况下多个线程同时修改一个数据时会出现冲突问题,这个以后再说)
线程运行的时候,在堆中创建了一个对象,然后再在栈上创建一个对象保存堆中该对象的地址,由此完成对大对象的处理,等线程结束了,栈上的保存堆对象地址的变量就会消失(因为该线程的栈空间被回收了),但是堆中的对象仍然存在,此时如果堆中占用的对象不销毁、占用的空间不回收,程序长时间运行、反复这样做,就会将内存空间耗尽,这肯定是不可以的。所以JVM有一套内存回收机制,当它发现堆中的对象没有任何其他对象保存了它的地址时(也就是再也没有人能够访问到它),就对它进行回收,这就叫垃圾回收,英文Garbage Collection,简称GC,JVM中有专门做这件事情的线程,我们通常称其为GC线程。
注意,在Java中,char、byte、int、long、float、double、boolean等这些基础类型(系统内置的、用小写字母表示的)的值,是保存在栈上的,其他的类型创建的值,都放在堆中,包括这些基础类型的包装类型Byte、Integer、Long、Float、Double、Boolean以及String类型和开发者自定义的数据类型。那么Java为什么要这么设计呢?这是因为基础类型的大小是固定的,栈空间处理这些固定大小的数据可以充分发挥性能优势还能避免GC,是非常好的设计,同样的,包装类型因为要和其他大小会变动的数据类型一起完成对现实世界的表达和抽象,自然就得在堆上了。
Java对象
现在,我们可以解释Java中对象的问题了,先看一段代码:
public class EqualsTest {
public static void main(String[] args) {
Integer a = new Integer(5);
Integer b = new Integer(5);
System.out.println(a == b);
System.out.println(a.equals(b));
}
}
上述代码中有一个equals方法,下面我们也着重介绍一下。在Java中,基础类型如int、boolean,是可以直接使用==判断它们是否相等的,但是对于包装类型、字符串类型和用户自定义的对象类型,是不可以的。对象类型的变量,==只能表明它们是否是同一个实例,却不能表明它们的值是否相同。请看下面的代码:
public class EqualsTest {
public static void main(String[] args) {
String a = new String("beijing");
String b = new String("beiJing");
System.out.println(a == b);
System.out.println(a.equals(b));
}
}
上面的代码和前面两个Integer类型的变量a和b的逻辑是一样的,都是第一个输出false第二个输出true。原因就是a和b都是new出来的变量,像Integer和String,它们都是在堆上的,所以它们肯定是有不同的内存地址的,a和b的值分别是它们的地址,那肯定是就不相等了,所以输出false,第二个调用的equals方法,就是将变量所指向的堆中的对象的值取出来进行比较,它们的值都是beijing,于是就输出true。
异常
异常机制
异常是指程序在运行的过程中出现的非预期场景,比如正在从网络下载文件,突然断网了,正在读写文件,突然文件被其他进程给删除了,正在读取U盘上的文件,突然U盘被人拔出了等等。当然,也包括一些相对前述这些“故障”级的异常而言没这么“严重”的情况,比如用户输入的两个数要相除,但是除数是0,此时无法进行进一步的计算,也算是异常。Java中的异常,体系如下:
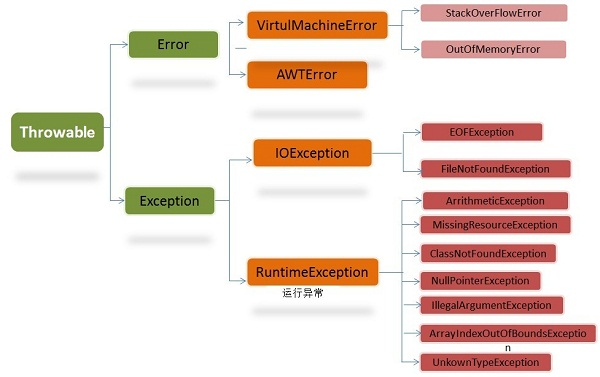
如上图所示,Java中的异常有两大类:
- Error 这种异常,通常是无法处理的,会导致进程完全崩溃,但是通过一些配置项,可以获得程序崩溃的一些详细信息,便于我们排除错误。这里最常出现的就是内部不足:OutOfMemoryError,业界通常简称为OOM。
- Exception 这种异常,如果代码中不捕获和处理,程序也会崩溃退出,如果在代码中予以必要的捕获和处理,则可以避免程序崩溃退出。例如用户输入了一个日期,但是我们的程序无法识别它的格式,可以捕获这种异常,然后提示用户输入不正确,请重新输入之类的信息。就能避免因为用户一次错误的输入而导致各个程序崩溃退出。
默认情况下,一旦程序出现异常,那么将会从出现异常的位置直接退出,该位置之后的代码将不会被执行。
抛出或声明异常
除了程序在运行中出现的各类异常,我们还可以在代码中手动抛出异常。代码也很简单:
throw new Exception();
throw关键字后面写一个Exception类或它的子类的实例对象,就可以抛出异常了。
在声明一个方法时,如果方法中有Exception抛出,那么该方法的定义部分要用关键字throws明确声明该方法可能有异常,让调用者知道并做一些必要的处理:
// 声明此方法在执行时有可能抛出两个异常
public static void method1() throws IOException, FileNotFoundException {
//something statements
}
// 声明此方法在执行时有可能抛出Exception异常
public static void method2() throws Exception {
//something statements
}
捕获异常
前面我们也提到了,Exception这种异常可以被捕获,那么具体怎么做呢?很简单的,使用try…catch就可以了,有其他编程语言经验的同学们肯定也已经想到了,下面我们一起来看一下吧:
try {
File f =new File("C:\\test.txt");
FileInputStream fis = new FileInputStream(f);
// todo something
} catch (FileNotFoundException e) { //子类异常
e.printStackTrace();
} catch(IOException e) { //父类异常
e.printStackTrace();
} catch(Exception e) { //基类运行时异常
e.printStackTrace();
}
System.out.println("continue");
在上述代码中,我们试图读取C:\test.txt这个文件,如果这个文件不存在,将会抛出FileNotFoundException,如果读取文件的过程中出现错误,将会抛出IOException,如果还有其他无法处理的异常,将会抛出Exception,这些我们都要捕获并处理掉,才能不让我们的程序崩溃退出。此时程序在执行完相关异常的catch代码块中的e.printStackTrace之后,将会继续往下运行,会打印输出continue,不会崩溃退出。
👉👉👉注意: 上述代码中的这三个异常,它们是有继承关系的,IOException是Exception的子类,FileNotFoundException是IOException的子类,所以,有多个catch代码块的时候,子类一定要写在前面,父类一定要写在后面。
因为我们已经通过异常机制的章节知道,所有非Error类型的异常都是Exception的子类,那么上述代码可以简化:
try {
File f =new File("C:\\test.txt");
FileInputStream fis = new FileInputStream(f);
// todo something
} catch(Exception e) {
e.printStackTrace();
}
即:如果某段代码执行时可能会产生多个异常,我们可以只捕获这些异常共同的父类(其实就是Exception了)。
在实际的应用软件开发中,如果出现异常,我们通常会将异常信息收集起来(通过catch块中的实例e的相关方法调用可以做到),然后记录在日志文件中或者某个地方,便于我们以后排查处理。
finally语句块
无论是否有异常,finally块中的代码总是会被执行的。 finally语句在执行关闭资源的语句时非常有用。如:无论读写文件是否出现了异常,我都选择将文件关闭,否则程序运行的时间一长,方法被调用的次数一多,就会出现文件被打开了许多份,就会造成资源泄漏和浪费,甚至是内存耗尽。
第一种形式:
try {
// 要执行的程序代码,可能会出现异常
} catch(Exception e) {
// 出现捕获时执行的代码,走到这一步,说明异常已经被捕获
} finally {
// 无论是否异常,一定会执行的代码
}
第二种形式:
try {
// 要执行的程序代码,可能会出现异常
} finally {
// 无论是否异常,一定会执行的代码
}
finally语句块很有用,在做一些需要加锁的操作时很有用,比如在做支付扣款操作时,要锁定账户,然后判断余额足够时才扣款,这样才能防止多个操作同时进行以至于把账号余额扣成负数。这个操作可以在刚进入try时加锁,然后在finally块中释放锁(如果不释放锁,会导致该账户被永久锁定,谁也用不了了,明显是不可以的)。
Maven简介
Maven是Java开发必备的一款依赖管理和代码构建工具。这么说是不是太抽象了?我们从问题的角度入手,做复杂的、大型、超大型软件开发的时候,有这么几个非常觉的问题:
- 依赖管理,比如我要做一个Redis数据库的连接池,让我基于Java语言现开发肯定是不太合适的,如果有现成的、别人开发好,直接用,他不香吗?要实现这个依赖自动管理,就又引申出一个新的问题:依赖的版本,这同样需要依赖管理工具帮助我们做,否则一个软件中引入多个版本的第三方代码库(包),很容易出现各种冲突和错误
- 构建编译,在软件开发的过程中,我们经常要写一点,编译运行一下,看看有没有问题,有问题就赶紧改,没有问题再继续写(如果你一口气写完整套软件,比如花了半个月,然后发现有问题再重新写?想想吧😒)。在这个过程中,反复保存、编译、运行、调度,这个过程太浪费时间、太痛苦了,我们必须要有一套自动化的工具,把我们的这个过程一键完成
- 代码组织规范,这其实是一个团队协作的问题,一个大型、超大型的软件,一定是很多人一起开发的,那么所有人都应该遵循一套规范,否则一个软件系统中五花八门的岂不是乱套了,还怎么组织代码?以后还要不要维护了(根据笔者的经验,新写代码的时间一般只占开发者20%的时间,剩下的时间都是在维护和修改😂)。
- 代码分析和检查,这其实是一个软件质量的问题,软件开发的过程中,我们要不断的对代码进行分析和检查,避免一些质量低下的代码被提交和编译运行,这会导致各种BUG,坑很深哦~
基于以上原由,我们是必须要有一套依赖管理和代码构建工具,才能高效地完成Java软件开发工作。而目前主流的就两个:Maven、Gradle,Maven在传统的Java开发中用的很多,Gradle也有人用,但更多的是用在Android开发中。
Maven安装配置
Maven的安装非常简单,只需要下载官方提供的压缩包,然后解压,最后再配置两个环境变量就可以了:
- MAVEN_HOME 指向具体的Maven软件包的目录
- MAVEN_OPTS 可选,用于指定Maven运行时的内存占用策略,配置方法和JAVA_OPS一样的,示例:
-Xms512m -Xmx1024m
最后,将MAVEN_HOME目录下的bin目录添加到系统环境变量中:
- 在Windows下,就是将%MAVEN_HOME%\bin添加到环境变量Path中,需要在系统设置中去修改,然后新开cmd或PowerShell才能生效
- 在非Windows系统下,就是将$MAVEN_HOME/bin添加到环境变量PATH中,在~/.bashrc中配置并导出即可,完成后运行命令
source ~/.bashrc使其立即生效
安装好之后,可以在命令行执行mvn命令,就能验证是否安装成功了(注意:Maven依赖于JDK,必须得先安装好JDK才能用Maven):
IDE与Maven协作
IDE是集成开发环境(Integrated Development Environment)的简写,通常是指具备软件工程化管理功能、代码编辑功能、编译运行、调试排错等综合功能的软件,对于Java开发来说,市面上最常见的两款IDE是开源的Eclipse和JetBrains的IDEA,前者是开源软件Eclipse基金会的,后者是一家专门为程序员开发各种IDE的厂商开发的商业化软件,IDEA只是其中之一。
这两款IDE,都内置了Maven,当然,我们也可以使用在操作系统中安装的我们自己的Maven,而且笔者更喜欢这么做,原因有如下:
- IDE内置的Maven,修改配置需要在IDE中,如果IDE更换或卸载重新安装,配置会丢失
- IDE内置的Maven,跟着IDE走,需要我们再额外地去掌握它的配置和使用,比较麻烦,而使用自己的,固定一个版本和一套配置,省事
- 特殊情况下,我可以修改我自己的Maven中的配置甚至代码,让它的工作符合我的预期,对于IDE中自带的Maven,那就没把握能修改了

对于Eclipse,只需要点击Window菜单,再点击Preferences,在里面找到Maven,就可以调整它的配置了,很简单的。

对于IDEA,其实也差不多,打开Settings之后,找到Build、Execution、Deployment,下面有个Build Tools,再下一级,就有Maven,调整它的配置就可以了,也很简单。
Maven使用简明教程
Maven配置文件
Maven的配置文件位于Maven安装目录中的conf目录下,名叫settings.xml。
注意:这里的配置文件中的项,会对使用这个Maven的所有软件工程生效。
它里面有这么几个重要项,我们分别解释一下:
- localRepository 下载的外部依赖保存到什么地方,默认是${user.home}/.m2/repository,按照我的个人在Windows上的习惯,我会把它挪到其他地方去,这可就可以避免如果我重装系统了,还要重新下载一遍
- servers 私服发布的账号和密码,这个配置一般在服务器上使用,在我们开发机器上一般不配置,通常的做法是:在Jenkins服务器或CI/CD服务器上配置好,然后打出来的包会直接进入公司自建的私服仓库,便于其他人使用
- mirrors 获取外部依赖的镜像位置,如果不配置,默认从官方仓库获取,在官方国外,很慢的,通常我们会在这里配置多个mirror,国内的阿里云、公司自建的私有仓库等
- profiles 个性化配置,也可以配置多个,我个人的经验是:先配置一个profile,指定JDK版本,比如JDK8,再配置其他仓库的地址,便于我们能从其他仓库下载依赖包
- activeProfiles 这个其实就是指定激活前面的profiles中配的个性化配置,当profiles中指定了多个配置的时候,可以在这里指定激活哪一个,通常,全局性的个性化配置我们才会在这里指定,其他的通常在软件工程中配置,否则会导致不同的软件工程使用个性化配置出现问题
下面贴一份示例配置:
<?xml version="1.0" encoding="UTF-8"?>
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<!-- 本地仓库的位置 -->
<localRepository>D:\repository</localRepository>
<!-- 阿里云镜像 -->
<mirrors>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
<!-- 配置: java8, 先从阿里云下载, 没有再去私服下载 -->
<!-- 注意: 影响下载顺序的是profiles标签的配置顺序(后面配置的ali仓库先下载), 而不是activeProfiles的顺序 -->
<profiles>
<!-- 全局JDK1.8配置 -->
<profile>
<id>jdk1.8</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.8</jdk>
</activation>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
</properties>
</profile>
<!-- Nexus私服配置: 第三方jar包下载, 比如oracle的jdbc驱动等 -->
<profile>
<id>team</id>
<repositories>
<repository>
<id>nexus</id>
<url>http://192.168.10.112:8081/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>public</id>
<name>Public Repositories</name>
<url>http://192.168.10.112:8081/nexus/content/groups/public/</url>
</pluginRepository>
</pluginRepositories>
</profile>
<!-- 阿里云配置: 提高国内的jar包下载速度 -->
<profile>
<id>ali</id>
<repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/nexus/content/groups/public/</url>
</pluginRepository>
</pluginRepositories>
</profile>
</profiles>
<!-- 激活配置 -->
<activeProfiles>
<activeProfile>jdk1.8</activeProfile>
<activeProfile>dev</activeProfile>
<activeProfile>ali</activeProfile>
</activeProfiles>
</settings>
你可以参照这份配置,做一些研究和修改,很容易就能自己用了。
通过Maven创建项目
在我们使用IDE的时候,通常我们都是使用IDE自带的创建项目的功能来新建一个软件工程,但是实际上它们仍然是通过Maven的这一套机制创建的。
创建普通的Java项目:
mvn archetype:generate -DgroupId=cn.ms11 -DartifactId=demo -DarchetypeArtifactId=maven-archetype-quickstart
创建一个Java Web项目:
mvn archetype:generate -DgroupId=cn.ms11.blog -DartifactId=myweb -DarchetypeArtifactId=maven-archetype-webapp
- mvn 是Maven的命令
- archetype:generate 是表示创建一个项目,archetype其实是原型的意思,表示Maven内置了很多原型模板(预定义好的项目模板),可以基于它们创建我们自己的项目
- -DgroupId 项目的组名称,按照Java开发约定,每个Java项目,都会有一个groupId
- -DartifactId 项目的制品输出名称,按照Java开发约定,每个Java项目,都会有一个唯一的artifactId,如果这个项目是你自己用的,随便起无所谓,如果是要和他人协作,就要起名专业、见名知义,如果是作为公开软件发行,就一定要起一个正式的、正确体现产品功能的名称,最好能做到唯一
- -DarchetypeArtifactId 引用的模板名称,这些模板,其实也是Java项目,只不过我们是照着他们的“模子”复刻了一份我们自己的,所以这些模板也会有artifactId,在这里,普通的Java项目我们引用的模板是
maven-archetype-quickstart,Java Web项目我们引用的模板是maven-archetype-webapp,大家注意这两个名字,以后我们还会经常和他们打交道。
普通的Java项目和Java Web项目有什么区别呢?普通的Java项目,顾名思义,就是它没有什么特别的,就是我们常规的一些Java类放在一起,然后写一个main方法,让它能够启动并执行,这是基于J2SE的,Java Web项目就不同的了,它是基于J2EE的、用于服务器端软件开发的一门技术,又称为企业级应用开发,这种开发技术比普通的Java开发要复杂的多,它要处理数据库中的数据、要开放服务给用户来访问网站,当网站用户量比较大的时候,还要想办法通过缓存提升性能等等。
J2EE是Java Web开发的一整套规范,这一整套规范共有13项,分别是:
- JDBC(访问数据库的,用的很多)
- JNDI(访问服务器资源的)
- EJB(业务逻辑抽取方法,用的人已经很少了)
- RMI(远程访问调用,仍然有很多老旧项目在用)
- JavaIDL(公用对象请求体系,用的也不多)
- JSP(曾经的网站页面开发,也就是Web开发的王者,现在已经没落了)
- Java Servlet(在服务器上处理请求、扩展服务器应用程序的能力,很常用)
- XML(一种数据描述语言,也挺常用的)
- JMS(Java消息服务,部分细分领域用的人挺多的)
- JTA(分布式事务,比较常用)
- JTS(事件监控,笔者也没用过)
- Java EMail(发邮件的,OA等系统中挺常用)
- JAF(数据处理框架,用的很少,现在的数据都有专门的数据仓储平台和框架)
关于J2EE的规范,了解一下就可以了,等你对Java Web的开发技术已经掌握的差不多的时候,再回过头来研究这些规范,会有更多的收获。
通过Maven打包
Maven打包是非常简单的:
mvn package
一个Java项目,可以被打成jar包或war包两种格式,具体打成什么,是由项目根目录下的pom.xml决定的。这个pom.xml的具体配置和用法,我们后面会学习到。
说起打包指令,我们还要顺便提一下安装指令和部署指令,安装指令:
mvn install
部署指令:
mvn deploy
这两个指令分别有什么用呢?这就要提到最开始我们学习Maven的时候说的Maven仓库了,Maven仓库本质上是一个OSS,也就是对象存储服务,大家把自己开发的各类软件组件、框架、类库上传到Maven仓库,就可以让其他人使用了。简单地说,Maven有四类仓库:
- 中央仓库,官方地址:https://mvnrepository.com/ ,在美国。所以访问和下载各种依赖都很慢。
- 镜像仓库,世界各地针对中央仓库的问题,都建立了本地化的镜像,在国内用的最多的是阿里云镜像,前面介绍Maven配置的时候提到的settings.xml中就有
- 私服仓库,私服仓库是针对企业内部使用的,一个企业内部有多个团队多人协作时,也需要解决某个团队开发的组件给其他团队使用的情况,也需要将这些组件上传到自己企业的私有仓库中便于他人随时下载和使用。私服仓库需要各企业自行搭建,最的最多的是Nexus,Nexus软件的官方地址:https://www.sonatype.com/products/repository-oss
- 本地仓库,这个是指Maven在运行时本机上保存的第三方依赖,Maven在打包时,会将第三方依赖下载下来放到本地仓库,然后直接从本地仓库读取使用。这个本地仓库,其实就是在本地磁盘上指定一个目录用于保存这些第三方依赖。具体的位置是在Maven的settings.xml中通过节点
localRepository指定的。
通过Maven执行测试
执行Maven的打包命令的时候,默认是会执行代码中的测试代码(就是位于src/test/java下的单元测试用例代码),所以,一般情况下如果我们写了测试的代码,更多的时候,是在某些情况下不执行测试,直接出包。具体指令:
mvn package -DskipTests
上述指令,不会执行测试代码,但是仍然会编译测试代码,如果我们既不想执行测试代码,也不想编译测试代码,那么可以使用下面的指令:
mvn package -Dmaven.test.skip=true
通过Maven清理编译信息
某些时候,我们想要把编译出来的字节码、配置等相关内容全部清理掉,然后重新开始编译打包,指令也很简单:
mvn clean
pom.xml文件简介
pom文件是Java开发中非常重要的一个文件,一个软件工程,必定有一个pom.xml文件,这是工程的配置文件,工程相关的基础信息(名称、groupId、artifactId等)、变量、第三方依赖、打包、测试等等的相关配置信息,全部都在这个文件中配置。在介绍pom.xml文件之前,先明确一个Maven管理软件代码的方式:一个复杂的规模庞大的软件系统,它通常会有很多个模块,这些模块有可能还有子模块,像这种树状的结构,Maven也可以很好的管理和组织起来,其实就是父模块、兄弟模块这样的逻辑关系,无论是父模块还是子模块,都会有一个Maven的pom.xml文件,并且会在这个文件中声明它们的父是谁、子有哪些。
我们先来个pom文件的模板示例,然后配合注释进行说明:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- 基本设置 The Basics -->
<groupId>...</groupId>
<artifactId>...</artifactId>
<version>...</version>
<packaging>...</packaging>
<dependencies>...</dependencies>
<parent>...</parent>
<dependencyManagement>...</dependencyManagement>
<modules>...</modules>
<properties>...</properties>
<!-- 构建过程的设置 Build Settings -->
<build>...</build>
<reporting>...</reporting>
<!-- 项目信息设置 More Project Information -->
<name>...</name>
<description>...</description>
<url>...</url>
<inceptionYear>...</inceptionYear>
<licenses>...</licenses>
<organization>...</organization>
<developers>...</developers>
<contributors>...</contributors>
<!-- 环境设置 Environment Settings -->
<issueManagement>...</issueManagement>
<ciManagement>...</ciManagement>
<mailingLists>...</mailingLists>
<scm>...</scm>
<prerequisites>...</prerequisites>
<repositories>...</repositories>
<pluginRepositories>...</pluginRepositories>
<distributionManagement>...</distributionManagement>
<profiles>...</profiles>
</project>
- 基本设置,这个很重要,每个工程都要配置,这个是重点,具体有以下几项
- groupId 你可以理解项目分类或分组的唯一标识符、ID,父模块中必须指定,子模块中通常不指定,直接使用父模块的。
- artifactId 构建出的成品的唯一标识符、ID,必须指定。
- version 构建出的成品的版本号,父模块必须指定,子模块中通常不指定,直接使用父模块的。
- packaging 打包方式,有三个最常用的值:pom、jar、war,以Maven方式创建的软件工程,如果软件很复杂,就需要拆分成很多个模块,这些模块可以统一使用父模块管理它们的依赖(当然,也支持多级继承,但是通常两三级也就够了),所以,对于父模块的pom.xml中的packaging,就应当指明为pom,普通的Java工程或不独立运行而是供他人使用的模块,通常都指定为jar(即:打jar包),传统的基于SSH或SpringMVC框架开发的Java Web项目,通常声明为war(即:打war包)。一般情况下,要独立地、直接运行的Java代码都会打为jar包(当然了,它里面要有一个main方法才可以),如果打为war包,通常会将打出来的包放到Tomcat(一款非常流行的Web应用程序容器)中运行。packaging如果没指定,默认为jar。
- dependencies 依赖定义,如果工程中使用了其他组件,就要在这个节点下定义。dependencies节点下可以有多个dependency,每个dependency是一个依赖项,每个依赖项还有几个重要的参数项:
- optional 用于控制依赖传递,假设A依赖B,B又依赖C,此时在A的pom.xml中引用B的依赖时,如果optional为true,则A只依赖B而不依赖C,如果optional是false,那么表示A依赖B同时也依赖C
- scope 用于控制依赖项的引用方式,默认值是compile,表示对依赖项进行编译并且打入目标包中,取值provided,表示使用依赖项,但是不打入目标包中(通常这种情况是由目标应用容器如Tomcat提供,所以见的多的是servlet的包用这种方式引用),取值runtime,表示运行和测试时需要该依赖,但打包时不需要,取值test表示编译和测试时都不需要,只在测试编译和测试运行时需要,取值system,表示从本地引用一个依赖的jar包,很少用,因为限制太多
- parent 这个对于子模块是必须的,用于指定本工程的父模块,这个配置项对于单独的Maven工程没什么意义,在现在SpringBoot框架的开发模式下,也可以通过继承SpringBoot官方定义的父模块快速地完成子模块的定义和配置,大大简化自己手动配置工程的每一个细节的过程,效率提升非常明显。
- dependencyManagement 依赖声明,注意,这个只是依赖声明,它和dependencies是不一样的。dependencies会将定义的依赖引入本工程中,是可以直接使用的,而dependencyManagement仅仅是声明本工程要使用某个依赖项,却并不会真正引入本工程。所以这个dependencyManagement通常是在父模块中使用。在父模块中声明使用哪些依赖,然后在子模块中按照父模块的声明通过dependencies进行依赖定义,这样就可以实现多个子模块的依赖管理统一到父模块中了,便于解决一些版本冲突等问题。通常情况下,一个复杂的软件工程,如果引入第三方依赖,应该统一版本号,防止各行其是,那样很容易出现各种各样的问题。
- modules 子模块声明,仅对父模块有用力,在父模块中,有哪些子模块继承了自己,要在这里声明出来,它和parent相对应,子模块中通过parent指明父模块是谁,父模块中通过modules指明都有哪些子模块,只有对应得上,才能编译打包成功。
- properties 变量声明,如果软件工程的配置中存在一个值多处使用的情况(通常是第三方依赖组件的版本号),我们就可以通过这个节点进行统一声明,避免到处写、到处维护的情况。
- 构建过程,只需要做一些必要的设置即可,不设置的情况下也有默认值。
- 项目信息设置,这个通常是开源项目才设置,企业内部项目一般都不设。
- 环境设置,这个通常是在一些特定情况下使用的,比如大型开源软件基金会发布和管理的软件项目上。
Maven工程的pom文件里面的知识点还是非常多的,配置项也很多,我们在这里先学习这些,在后面的开发学习中,我们会逐步接触到更多的相关用法。
🍬 使用Maven管理Java代码工程是使用的最广泛的一种方法,它的最基本的实践套路是:当我开发软件的时候,需要一个特殊的功能(比如密码加密、校验手机号码、发送网络请求、访问数据库等等),我不需要自己从头开始一行一行写代码,我去找一个第三方框架,别人已经写好的,直接拿来用(Java开发中最强大的Spring框架就带了这方面的很多很多功能)。要想把别人写好的东西拿来直接使用,不是将对方的代码拷贝到自己的软件代码包中,而是在自己工程的pom中的dependencies节点或dependencyManagement中写上对方的依赖项,将对方引入到自己的软件工程中来就可以了。那么,对方的依赖上哪儿去找呢?Maven的中央仓库里是最全最完整的,官网站点:https://mvnrepository.com/ 或者你觉得访问这个网站太慢,你还可以通过搜索引擎的关键字maven repository都能找到Maven仓库,去仓库中搜,还可以去技术博客、社区和其他人交流,都能快速掌握这些技能,找到优质资源。
Maven插件使用
Maven本身仅仅拥有一个具备高度灵活和可扩展的软件架构,但是在编译打包的过程中,还有很多事情要做,比如是否将源代码也打到包里、是否生成javadoc、是否自动生成一些代码之后再打包等等。在这方面,官方提供了很多插件,方便我们打包,当然,我们也可以自己开发插件实现更复杂的功能。这里我们就先说说怎么使用插件吧。
> javadoc是指将Java代码中的注释生成HTML,便于其他开发人员阅读和理解代码。
在Maven项目上使用插件,具体做法是修改项目的pom.xml文件,示例:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.companyname.projectgroup</groupId>
<artifactId>project</artifactId>
<version>1.0</version>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring.boot.version}</version>
<executions>
<execution>
<goals>
<goal>package</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
上面这个配置文件,是指定了插件spring-boot-maven-plugin,这个插件是用来编译打包SpringBoot工程的,当然如果有多个插件,就在plugins节点下再增加plugin节点,如法炮制即可。还可以插件节点下的glals中配置多个goal,Maven中常用的goal是archetype、compile、test、jar、install,看名称就知道了它们是做什么的了(Maven中的goal是一个比较复杂的话题,其中还激活到Maven管理项目的生命周期的问题,这属于高级话题,我们可以以后再学)。
字节码
我们所写的Java源代码文件是这样的:
package com.wasu.t.c;
public class CodeFileDemo {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
编译后的字节码文件是这样的:
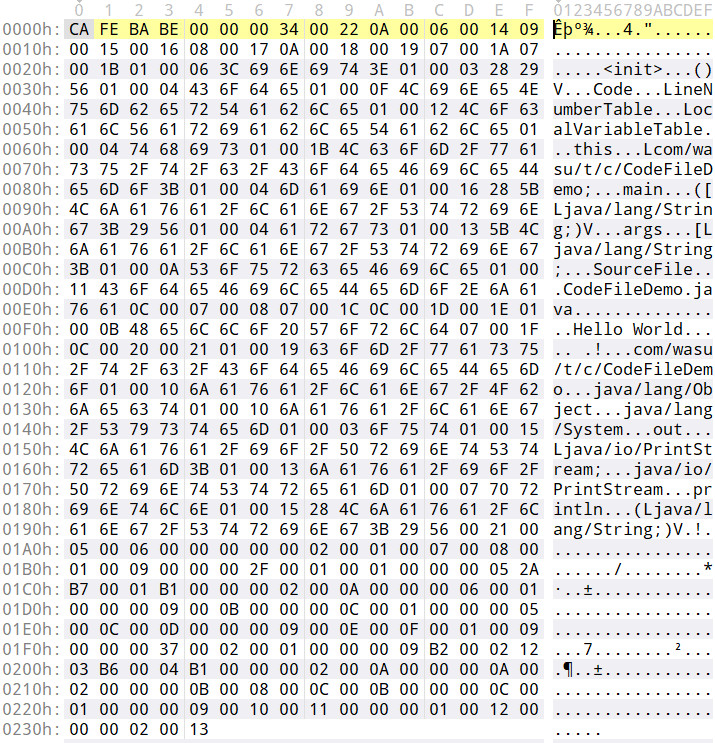
最开头的那几个字符CA FE BA BE,通常被称为“魔数”,是JVM识别.class文件的标志,不符合这种标志规范的,它不会加载。
我们还可以反编译这些.class文件,在.class文件所在位置执行下面的指令:
PS E:\code\ideaWorkspace\test-any\target\classes\com\wasu\t\c> javap -c -l .\CodeFileDemo.class
看看它到底是怎样的字节码信息:
Compiled from "CodeFileDemo.java"
public class com.wasu.t.c.CodeFileDemo {
public com.wasu.t.c.CodeFileDemo();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 9: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/wasu/t/c/CodeFileDemo;
public static void main(java.lang.String[]);
Code:
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String Hello World
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 11: 0
line 12: 8
LocalVariableTable:
Start Length Slot Name Signature
0 9 0 args [Ljava/lang/String;
}
每个字节码指令,都有它特定的含义:
- 第3行,是默认的构造方法,当我们没有为类指定时,编译器会自动添加一个
- 第5行aload_0,是从本地变量表中加载索引为0的变量的值,也就是this,然后压入栈
- 第6行invokespecial,出栈,调用java/lang/Object."<init>":()V初始化this指定的对象,具体就是调用this指向对象的init方法
- 第8行LineNumberTable,指令与代码行数的偏移对应关系,每一行有两个数字,第一个是代码行数,第二个是前面Code节中的的指令前面的数字,本例中,line 9: 0的意思是:代码的第9行就是本字节码文件中的Code节中的0,也就是aload_0(这一小段文本中的第5行)
- 第10行LocalVariableTable,局部变量表,本例中,只有this这一个变量
其他详细信息我们以后再说。
类加载过程
JDK的类加载过程如下图所示:

如图,加载、验证、准备、初始化,这四个阶段的顺序是固定的,解析,在某些情况下,解析可能在初始化之后开始,这样做是为了支持Java的运行时绑定(也称为动态绑定或晚期绑定)。
- 加载(Loading),这是类加载过程的第一个阶段,主要是将字节码从不同不的源(class文件、jar包、甚至网络字节流等)加载到内存并生成一个代表该类的
java.lang.Class对象
- 链接,这是类加载过程的第二个阶段,分为验证、准备、解析三个步骤
- 验证(Verification),是为了确保被加载的class文件是符合JVM规范的,否则会导致一些意外情况和安全问题,主要包括四种验证:文件格式、元数据、字节码、符合引用,总之,是为了确保被加载类的正确性
- 准备(Preparation),是为类的静态变量分配内存,并将其初始化为默认值(如:有static int a = 5这样的语句,此时a的值是int的默认值0,经过了后面的初始化阶段之后它的值才会变成5),但不包含final修饰的static变量,因为final修饰的变量是在编译期确定的。此外,类变量在JDK7及以前会分配到方法区中,JDK8及之后会分配到Metaspace中,实例变量会分配到Java堆中。
- 解析(Resolution),把常量池中的符号引用转换为直接引用。这句话的意思是:类
com.A引用了类com.B,在编译阶段,类A并不知道类B的地址,所以,在类A中对类B的引用,只能描述为com.B,这就是符号引用,而加载类时,因com.B被加载,JVM就知道类B的地址了,此时就需要在类com.A中将类com.B的地址转换成真正的地址(类A对类B的真正的地址的引用,就是直接引用,也只有这样,类A在执行的时候,才能它所依赖的B)
- 初始化(Initialization),这是类加载过程的第三个阶段,主要是为类的静态变量赋予正确的初始值。如果类有父类,就先对父类进行初始化,执行其静态初始化器(也就是用static修饰的静态代码块)和静态成员变量的初始化(对static修饰的类成员变量,在准备阶段已经有初始的类型默认值了,在这里会对它进行赋值,让它的值是源代码中指定的默认值)。类的构造器也会在这个时候执行。
所谓绑定,是指把一个方法的调用和方法所在类关联起来(否则就会出现方法找不到类、类找不到方法的情况),Java中有动态绑定和静态绑定两种:
- 静态绑定是在编译阶段就确定的,如果类的方法是final、static、private,那么它就是静态绑定的,构造方法也是静态绑定的,静态绑定也称前期绑定
- 动态绑定是在运行阶段绑定的,是代码运行时根据具体对象的类型进行绑定,非静态绑定的,就都是动态绑定,它占大多数,动态绑定又称运行时绑定
类加载器
通常情况下,我们写一些简单的程序,不需要和类加载器打交道,但是复杂一点的情况下,我们仍然需要使用它们,下面我们就了解一下Java中的类加载器。
首先明确一点:一个类和这个类的加载器一起在一个JVM中确定唯一性。换个说法:同样的一个class文件,使用两个类加载器分别加载,那么它在JVM中是两个Class对象(也就是两个类),调用这两个对象的equals方法会返回false。
Java中有下列加载器:
- Bootstrap ClassLoader 有人称之为引导类加载器,负责加载$JAVA_HOME/lib/rt.jar中的所有class文件,由C++实现,这个加载器不是JDK中定义的ClassLoader这个类的子类
- Extension ClassLoader 负责加载$JAVA_HOME/lib/ext/*.jar中的所有class文件,还可以加载由-Djava.ext.dirs选项指定的目录中的jar中的class
- App ClassLoader 也称为SystemAppClass,加载当前应用程序的CLASSPATH中的所有class
- Custom ClassLoader 用户自定义类加载器
想要知道当前代码的类加载情况,可以尝试运行下面的代码:
public class ShowLoadedClass {
public static void main(String[] args) {
ClassLoader loader = ShowLoadedClass.class.getClassLoader();
while (loader != null) {
System.out.println(loader.toString());
loader = loader.getParent();
}
}
}
输出结果:
sun.misc.Launcher$AppClassLoader@18b4aac2
sun.misc.Launcher$ExtClassLoader@28d93b30
每个 Java 类都维护着一个指向定义它的类加载器的引用,通过类名.class.getClassLoader()可以获取到此引用;然后通过loader.getParent()可以获取类加载器的上层类加载器。所以,输出结果的第一行是应用类加载器,第二行是扩展类加载器。
> 按照JVM规范,扩展类加载器的上层类加载器是启动类加载器,但在我这个版本的 JDK 中, 扩展类加载器的 getParent() 返回 null。所以没有输出。
!> JDK9之后实现了模块化,类加载器的工作过程和本文表述的不同,但是考虑到目前用的人很少,先不介绍了。
双亲委派机制
双亲委派机制的核心是:当某个类加载器要加载某个类时,该类加载器不直接加载,它会先询问自己的上级类加载器是否加载了,如果上级类加载器已经加载了,就不再重复加载,如果上级类加载器没加载,它自己才加载。
由上述描述可知以下几个关键点:
- 防止重复加载同一个.class。通过委托去上级询问,如果加载过了,就不再加载,保证数据安全,也可以避免“其他人写了一个和JDK中的包名类名完全一样的类就能使得JDK不使用自己的类而使用其他人写的类”这种危险的事情
- 保证核心.class不会被篡改,如上一条所示,Java通过固定的方式去加载自己有的类,别人的类是无法“冒充”JDk中的类的,即使篡改了,也加载不了,即使加载了,也不同一个Class对象。这样就保证了Class类的执行安全
动态加载类
动态加载类,是指一个Java程序在编译期间没有的类,在运行期动态加载进来。这种方式,可以实现很灵活的程序功能扩展。例如:我们定义一个接口Flyable,再写一个类Bird实现该接口,然后在代码中设计这样一个机制:运行时,当用户的输入是chicken时,将去指定的目录中加载Chicken这个类并执行它实现了Flyable接口的方法。然后我们将代码发布版本运行起来,运行中,我们动态的编写一个Chicken类并实现Flyable接口,然后将编译好的Chicken.class文件放到指定位置去,然后在程序的输入位置输入chicken,此时,程序不必重启,不必重新发布版本,就可以实现扩展新功能。
在实践中,动态加载类涉及到的问题很多,比如重复加载问题、卸载问题、资源占用问题、引用释放问题等,还是比较复杂的,本文作为初学者文章,大家知道这样的机制,会简单地使用就可以了。
什么是泛型
所谓泛型,简单的理解,就是你在写代码的时候,不知道它是什么类型,它是由程序运行中动态决定的。举例:JDK中编写了一个java.util.List,这个List中存放什么呢?这个问题很容易回答,因为JDK的开发人员在编写JDK的代码的时候,肯定要面临一个问题:除了JDK中自带的那些类型,开发者还能自定义类型,怎样将开发者后面使用JDK的时候自定义的类型也能放到List中去呢?这个时候如果你将一个List中可以保存的数据的类型固定死,那明显就不成了。一个List中,既存放了学生、又存放了食品、还存放了数字,那岂不是乱套了,就算不乱,代码处理这个List的时候得多复杂?
所以,开发JDK的人,就在编写java.util.List的代码的时候,没有明确这个List中存放什么,而是让开发者在使用java.util.List的时候去指定,这样就实现了:定义接口或类时,该接口或类所使用的其他类型未知,使用该接口或类时,能够明确该接口或类所使用的其他类型是什么。具体在Java语法上,使用一对尖括号和中间一个字母来表示,类似于<T>,当然了,这个也分多种情况:
- 定义一个接口,它的功能是对某个类实现特定功能(如序列化、转换等等),什么类呢?未知,使用该接口时才确定,那么在定义这个接口时用<T>表示,T即Type之意
- 定义一个接口或类,引用了另外一个类型,什么类型呢?未知,使用该接口或类时才确定,那么在定义这个接口时用<T>表示,T即Type之意
- 定义一个容器,这个容器中存放什么类型的数据呢?未知,使用该容器时才能确定,那么在定义这个容器时用<E>表示,E即Element之意
- 定义一个键值对的映射关系表(类似于汉语字典中的一个汉字对应一篇解释文章),键是什么类型呢?未知,使用它时才能确定,所以定义时用<K>表示,K即Key之意,同例,值用<V>表示,取Value之意
如果你理解了上述这些东西,就说明你知道什么是泛型了。
Java中最常见的java.util.List的定义是这样的:
public interface List<E> extends Collection<E> {
// 内容省略
}
这是指列表List或容器Collection中存放什么东西未知,取Element之意,简写为E。
JDK8中的Optional的定义是这样的:
public final class Optional<T> {
// 具体内容省略
}
Java中最常见的Map(键、值对映射关系表)是这样定义的:
public interface Map<K, V> {
// 具体内容省略
}
这个稍有特殊,它是指一个被定义了泛型的Java类或接口,其实可以支持多个泛型声明,即:这个接口或类在编写时,引用了多个其他类型,被引用的多个其他类型都是在代码运行时动态决定的。当然了,通常最多也就是2个,太多了就会复杂代码的复杂度,反倒有害。
怎么使用泛型
知道了什么是泛型,怎么使用泛型就很简单了,看下面的示例:
List<Integer> numbers = new ArrayList<>();
这段代码的完整形式是这样的:
List<Integer> numbers = new ArrayList<Integer>();
很明显,定义ArrayList的时候,指明它里面存放的是Integer类型,声明List变量的时候,指明它里面存放的是Integer类型。这样一来,就只能在这个numbers中放整数而不能放其他内容。这对于代码约束和规范,防止数据意外错乱是非常有帮助的。
我们自己定义泛型的时候,有可能有一种特殊情况,例如:类A类和类B都是预置好的,现在有个我自定义的MyList,它和List一样是个容器,里面我想让它既能放A又能放B(当然,它们的子类也可以放进去),这个要怎么弄呢?其实也很简单,我们只需要给类A和类B抽象一下,搞一个它们的父类或接口,让它俩去继承这个父类或接口,就可以了,比如搞一个父类:
class Parent {}
class A extends Parent {}
class B extends Parent {}
此时,我定义我的MyList,让它支持泛型(定义时不指定类型,使用时指定类型),如下所示:
class MyList<T extends Parent> {}
接口也是一样的,就不赘述了。
类型擦除
Python语言由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计。
Python语言提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
本栏目的详细内容正在建设中…
泛型的擦除,你可以这样简单的理解:编写代码时,指定用某某类型,但是运行时其实它并不存在(在动态运行中的代码是获取不到当初编写代码时写的那个泛型的),因为在编译时把它换了,比如换成了Object(以List为例,反正你放进去的时候是Object、取出来的时候还是Object,它该是数字始终是数字,该是字符串始终是字符串,不会出现无法识别或解析不了的情况)。可问题是:编写代码时写了泛型,编译时又擦除了泛型,为什么要这么做呢?其实原因也很简单:
- 代码是写给人看的,却是写给机器执行的,想要让人容易看懂,快速看懂,明确指定List中放的到底是什么类型,是很有必要的
- 有利于代码重用,我总不能有N个数据类型,就定义N种List,现在有了泛型,我只要定义一种泛型List就可以了,代码不会很冗余,真有修改,就改一处,不必把所谓的所有类型的List都改一遍,成本也低很多
至于运行嘛,当然是毫无影响的,反正都是堆上的对象。
最后一个问题:将所有写的泛型都擦除为java.lang.Object明显有点离谱,我们遵循下面这些约定:
- 若泛型类型没有指定具体类型,用Object作为原始类型,如:List numbers = new ArrayList(),我们不推荐这种写法
- 若有限定类型< T exnteds XClass>,使用XClass作为原始类型,如:class Score extends <T extends Person>,类型擦除之后是Person
- 若有多个限定<T exnteds XClass1 & XClass2>,使用第一个边界类型XClass1作为原始类型
列表(List)
列表,就是“一组”相同的东西放在一起,就组成一个列表,然后“放在一起”的方式,又分为两种:
- 很紧凑的放在一起,这就是数组,很显然,这种结构从中找到某个东西很快,从头到尾找一遍,很容易就找到了
- 很松散的放在一起,这就是链表,很明显,前后不紧挨着,那么要处理三种情况:
- 前面的人记住后面的人的位置,这样才能从前面的人找到后面的人,然后继续往后找,不然就断线了
- 后面的人记住前面的人的位置,这样才能从后往前找,不然就断线了
- 前面的人以后面的人的位置,后面的人也记住前面的人的位置,这是双向链表,从前往后找可以,从后往前找也可以
注意:是相同的东西才可以放在一起,这和其他弱类型的语言(如JavaScript)不同。
关于数组和链表,网上有一张图,我们借用过来看一下它们的区别:

数组的使用
定义数组:
int[] numbers = new int[3];
定义并且初始化:
int[] numbers = new int[]{1, 2, 3, 4};
String[] names = new String[]{"jack", "john", "james"}
定义并且初始化的时候,可以不必指定数组的长度,编译器会自动处理。
只取数组元素的方式遍历数组:
int[] numbers = new int[]{1, 2, 3, 4};
for (int number : numbers) {
System.out.println(number);
}
取数组的同时取数组元素的下标位置(下标位置从0开始):
int[] numbers = new int[]{1, 2, 3, 4};
for (int i = 0; i < numbers.length; i++>) {
System.out.println(i + ":" + number);
}
运行上述代码可以得到,数组int[]{1, 2, 3, 4}的4个元素的下标分别是0、1、2、3,数组的长度是4
从数组中找到某个元素是否存在,通常代码这样写:
public int indexOf(int[] numbers, int value) {
for (int i = 0; i < numbers.length; i++>) {
if (numbers[i] == value) {
return i;
}
}
return -1;
}
逻辑很简单:如果在numbers中找到了value,就返回value的下标,如果没找到,就返回-1。但是请注意,下面的代码是有问题的:
public int indexOf(String[] numbers, String value) {
for (int i = 0; i < numbers.length; i++>) {
if (numbers[i].equals(value)) {
return i;
}
}
return -1;
}
系统内置列表方法
Java的JDK中内置列表我们最常用的是两个:ArrayList和LinkedList,前者本质上就是一个数组,后者就是一个链表。只不过它们还提供了很多方法供我们很方便的使用,比如添加元素、查找元素、删除元素等等。它们有一些常见的方法,简单列举一下:
- size() 获得元素数量
- isEmpty() 判断是否为空列表,其实就是大小为0,即:size() == 0
- contains() 是否包含某个元素,判断时会调用元素的equals方法
- toArray() 转换为数组
- toArray(T[]) 转换为指定类型的数组
- remove(E) 删除一个元素,判断依据依然是调用元素的equals方法
- remove(int) 删除指定索引位的元素
- containsAll() 是否包含一个子列表
- addAll() 添加了个子列表
- clear() 清空
- retainAll() 取差集
- sort() 排序,此时元素必须实现Comparator接口
- get(int) 获得指定索引位的元素(索引位从0开始)
- set(int, E) 更新指定索引位的元素
- subList(int, int) 切分子列表
上面这些方法中提到的E,以及你去看List的源码的时候,还有尖括号中的T,都是泛型,所谓泛型,就是指代码在编写的时候不指定类型,在调用的时候、初始化的时候才指定类型。
列表使用注意事项
JDK中的ArrayList和LinkedList,有几个知识要点,我们在这里罗列一下:
- 不能并发删除,这会导致元素序列错乱,它们不是线程安全的
- 如果在操作元素的时候会有删除操作,最好使用迭代器Interator,然后做判断,既不要使用传统的for…i循环,也不要使用增强for循环,代码示例:
// 准备数据
List<Integer> numbers = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
// 遍历删除
Iterator<Integer> iterator = numbers.iterator();
while (iterator.hasNext()) {
Integer number = iterator.next();
if (number.equals(1)) {
// 使用迭代器的删除方法删除
iterator.remove();
}
}
- 调用Arrays.asList()生产的List不可以使用add,remove,这是由Arrays.asList() 返回的市Arrays的内部类ArrayList, 而不是java.util.ArrayList。
- java.util.List中的subList方法,是返回list的一部分的视图,注意,是视图,不是一个全新的子列表,所以,这个视图的存在,是依托于原来的List而存在的,查看源代码即可知道,subList返回的是通过
java.util.ArrayList.SubList#SubList这个内部类生成的,它里面还有parent指向上一层外部类。因此修改这个所谓的子列表,会影响原列表,反之,如果父类被修改了,那内部类的子列表依托于谁呢?它就无法解释了,所以,就会抛出一个ConcurrentModificationException。
- ArrayList存在一个扩容问题,ArrayList初始容量为0(创建时未指定大小),在第一次添加元素时,会进行扩容,此时容量为默认的10,之后每当向集中中添加元素达到上限时,进行扩容,扩容为原来的1.5倍。注意:这里指的是JDK7的情况,JDK6及之前,创建ArrayList对象实例时,初始容量直接是10,不存在第一次添加元素时扩容到10的操作。
映射(Map)
映射其实是一种数据的逻辑结构,它和存储结构无关,逻辑上,数据和数据之间存在一一对应关系,就会形成键值对,比如一个身份证号对应一个手机号,相信看到这里,有人会说不对,一个人可以办多张手机卡的,确实如此,但是我们在这里讨论的核心逻辑,是以一个确定的要素去对应另外一个确定的要素。
HashMap简介
Java中映射类型(键-值对)有好几种,最常见的、用的最多的,就是HashMap,本文为初学者计,暂时只探讨HashMap,这些知识也可供有经验的程序员同行们参考。
HashMap里面存放的是键值对,一个键对应一个值,好比书本的目录和文章、字典的索引和字义解释文章等。所以称之为映射。
HashMap使用
HashMap的使用非常简单:
HashMap初始化
Map<String, Integer> m1 = new HashMap<>();
Map<String, Integer> m2 = new HashMap<>(32);
Map<String, Integer> m3 = new HashMap<>(32, 0.5);
m1的定义,是初始化一个HashMap,一切依照默认值,初始容量大小是16,负载因子是0.75
m2的定义,是初始化一个HashMap,指定初始容量大小是32,负载因子是默认的0.75
m3的定义,是初始化一个HashMap,指定初始容量大小是16,负载因子是0.5
负载因子是扩容的时候用的(数据多,存不下了,就要扩大容量,称为扩容)。具体后面有讲解。
HashMap存取数据
m1.put("s1", 1);
m2.put("s2", 2);
m1.get("s1");
m1.getOrDefault("s1", 0);
- 存入数据时,如果原来这个Key下没有值,就返回null,如果原来这个key下有值,就返回前一个值
- 取得数据时,如果key下没有值,返回null
- 可以将一个Map直接整个放入另外一个Map,示例代码:
m1.putAll(m2),当然了,两个Map的Key和Value要一样,否则会报错的
- 可以将一个值放入Map的时候设置如果有值,就不放入,没有才放入,调用
m1.putVal(key.hash(), v, true, true)即可,第三个参数如果传true,就能实现有值不操作,无值就放入,如果第三个值传false,无论是否有值了,都放入(这样会更新以前已经存在的值)
- 取得值时,可以指定不存在的时候的默认值(JDK8中才有),示例代码:
m1.getOrDefault("s1", 0)
HashMap遍历
遍历HashMap有好几种方法方法,假设我们有这样的HashMap定义:
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
同时需要值和值时,通常这样操作:
for(Map.Entry<Integer, Integer> entry : map.entrySet()){
System.out.println("key: " + entry.getKey() + ", value: " + entry.getValue())
}
单纯的使用Key:
for (Integer key : map.keySet()) {
System.out.println("Key: " + key);
}
单纯的使用Value:
for (Integer value : map.values()) {
System.out.println("Value: " + value);
}
使用迭代器:
Iterator<Map.Entry<Integer, Integer>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry<Integer, Integer> entry = entries.next();
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
HashMap原理
HashMap的原理是非常重要的,原因如下:
- 这个数据结构太常用了,用的实在太多了,所以非常熟悉它是很有必要的
- 这是各科技公司、互联网大厂面试必问题
源代码剖析
Map是一个接口,HashMap是一个类,它实现了Map这个接口。
在cnblogs上,大神张铁牛发布的博文中,有一张图说明了JDK8中HashMap的结构(JDK7及以前的有所不同,这里只讲JDK8的),借来一用:
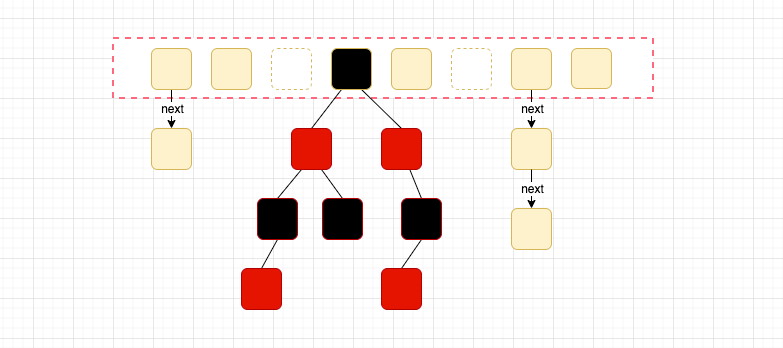
简单地说,HashMap内部其实是一个数组,每个数组元素称为一个Hash桶,这个所谓的Hash桶,默认情况下它是个列表,当有数据存进来的时候,根据数据计算一个它的Hash值(就是数学上的散列函数),然后再经过一些处理,就能计算出一个数组下标,此时就知道该数据要往哪个数组元素所在位置下的列表里放了(也可称这个过程中为散列到指定的哈希桶中去),要想弄清楚上图中HashMap的这些特性,我们先看它的源代码java.util.HashMap中的一些关键信息:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;
transient Node<K,V>[] table;
transient Set<Map.Entry<K,V>> entrySet;
transient int size;
transient int modCount;
int threshold;
final float loadFactor;
}
上述源代码中,我们剔除了其他很多东西,先盯这些重点。另外,对于有其他编程语言经验的人来说,可能不太习惯这种查看JDK源码的习惯,比如用VC++、QT、Python等,都是习惯于大量查阅官方文档的。但是对于Java来说,源代码就是最主要的手段,源代码中的注释文档也是比较丰富的。
上述HashMap类的主要字段我们逐个介绍一下:
- serialVersionUID 很多类都有这个,是用来序列化的时候用的,简单地讲,JVM如果收到了一堆字节流,要判断这个字节流能否生成一个本地的Java类的实例,众多的工作中,比较收到的字节流中的serialVersionUID和本地相应的实体类中的serialVersionUID是必须要做的,如果不一致,就会报
InvalidCastException
- DEFAULT_INITIAL_CAPACITY 默认容量,必须是2的n次方,`
1 << 4就是将1向右移4个Bit位,那么0001就变成了1000,也就是2的4次方,16,额外说一句,位运算的效率还是比较高的
- MAXIMUM_CAPACITY 最大容量,默认2的30次方,大约是10亿
- DEFAULT_LOAD_FACTOR 负载因子,HashMap有一个自动扩容机制,即:定义的时候有个默认大小(也可以手动指定),如果往里添加元素多了,容量不够放不下了,就会扩容,那么时候扩容呢?其实很简单,已有元素数量达到总大小的一定比例的时候扩容,这个负载因子就是这个比例,默认的0.75f当然就是75%了
- TREEIFY_THRESHOLD 树化阀值,当HashMap所持有的数组中某个元素索引位置指向的列表(Hash桶)的大小超过这个值时,会将该列表转换为一个红黑树,为什么要这么做?当然是为了提高存取数据的效率了,列表比较长的时候效率下降太严重,红黑树可以使用二分法查找,效率会快很多
- UNTREEIFY_THRESHOLD 反树化阀值,当某个Hash桶中的红黑树的节点数量小于这个值时,转换为列表,较小的数据量就没必要用红黑树了,正常情况下也挺快的,用红黑树,元素出入变动都会导致树的再平衡,反倒增加了额外的开销
- MIN_TREEIFY_CAPACITY 最小树化容量,当整个HashMap中的元素数量(每个Hash桶中的所有元素数量的和)超过这个值时,也会将Hash桶中的列表转化为红黑树
- table 存储数据的数组,每个数组元素都是一个
Node<K,V>,也就是哈希桶,它不能被序列化,一般情况下没事,特殊情况下会有问题,比如使用Groovy在Jenkins的Pipeline中处理Map时(因为此时它是通过文件走I/O来处理的,有序列化和反序列化的过程)
- entrySet 将所存储的数据以Set的形式存储,便于循环迭代,也不支持序列化,具体情况和table相同
- size 元素数量
- modCount 统计该HashMap实例中数据被修改的次数,这个值在循环迭代时判断HashMap是否被意外修改时会用到,主要是为了实现fail-fast机制,注意:HashMap不是线程安全的,不能多个线程同时修改它
- threshold 扩容阀值,元素数量达到这个值时进行扩容,和负载因子配合使用
- loadFactor 负载因子,DEFAULT_LOAD_FACTOR是默认的0.75,这个是构造初始化的时候可以让使用者指定的
所谓fail-fast机制,简单的理解,就是快速失败,这个有什么用呢?我们假设一个场景:我有一个100万个元素的HashMap,当我循环遍历到第100个的时候,它被人意外修改了,这个时候程序应该立即提示错误而不是把这100万个元素都遍历完了才提示错误,因为这样做既没有意义(前面的都出错了,还往下走,很有可能会让错误更加严重),又浪费时间。
构造器
HashMap还有3个构造器:
> 初始化一个默认容量=16,负载因子=0.75 的hashMap对象
public HashMap() {
// DEFAULT_LOAD_FACTOR = 0.75f
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
初始化一个指定初始容量和负载因子=0.75 的hashMap对象
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
初始化一个指定初始容量和负载因子 的HashMap对象
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
HashMap的内部类
HashMap中的内部类:
- Node 这是一个能够存放键-值对的类,HashMap的主干就是一个Node数组,或说者Node是HashMap的最基本组成单位,它实现了
java.util.Map接口中的Map.Entry<K,V>这个子接口
- KeySet 这是HashMap中键的集合,是个Set,继承自
java.util.AbstractSet,你可以理解它类似于字典或书本的目录,不能重复、便于检索内容
- Values 这是HashMap中值的集合,本身也是个集合,继承自
java.util.AbstractCollection,但是要注意,这并不代表在HashMap中可以一个键对应多个值,这是不对的,HashMap始终是一个键对应一个值,这就好比新华字典中的目录中的每一个字,对应字典正文中的一篇释义(为了便于理解我这么举例,多音多义的事情在此忽略吧),但是为什么值却是一个集合呢?因为键在计算哈希的时候,是有可能计算的一样的,比如HashMap的大小是16,存入数以万计的数据的时候,键重复了就意味着通过键保存到HashMap中的Node这个数组的数据的下标会冲突,这岂不是导致后来的数据覆盖了前面的数据?这当然不行了,所以值就是个集合,后来的数据如果发现对应Node数组索引位置没数据,就创建一个集合放进去,如果有数据了(集合不是NULL了),那就添加到集合中
- EntrySet 条目集合,这个内部类用于保存HashMap成员的键值对,换句话说,这个集合中的每一个元素,都是一个键值对,继承自
java.util.AbstractSet,也是为了便于遍历和查找
- TreeNode 二叉树,这是用于保存树状的值集合的,每个键下面都会有很多个值,将它们保存成为树,便于查找,效率很高
- 还有好几个以Iterator结尾的迭代器,也是为了便于快速访问而设计的
> HashMap是非常常用的一个数据结构,由上述内部类我们可以看出,还是蛮复杂的,JDK8中的
java.util.HashMap这一个类的实现就有2398行,复杂度可见一般,但是它使用起来非常高效,这也是得益于JDK开发团队的精妙设计,因此它的源代码值得每一位高手好好研学。
HashMap的扩容机制
JDK7下扩容机制:
JDK7的HashMap在扩容时,调用resize方法,此时会创建一个新的table,然后调用transfer方法将旧的数据放到新的table中,并且使用的是头插法,因此:
- 新table中的Value下列表中的元素的顺序和旧的是相反的,这也是为什么线程并发操作一个HashMap的时候有可能导致死循环,因为这个扩容的过程有可能导致一个环状节点形成,当然就死循环了
- transfer方法中的while循环就是头插法的操作过程
定义HashMap时,会完成默认容量、扩容阀值等项的设置,此后,第一次调用put方法入数据的时候,会初始化内部的Node数组,调整它的容量(容量变为不小于指定容量的2的n次方),然后计算扩容阀值,如果不是第一次扩容,新容量是旧容量的2倍进行扩容。
JDK8下扩容机制:
JDK8的HashMap在扩容时,先计算一个新容量的大小,它是旧容量大小的2倍,然后循环原table,将原来的每个Hash槽中的列表存入新table中。第一次调用put方法入数据的时候,初始化内部的数组并设置容量、扩容阀值等项,这是第一次初始化操作,有人称这是第一次扩容,如果不是第一次调用put方法,不再做初始化的操作,直接入数据,然后判断是否需要扩容,如果需要,容量扩大2倍。
HashMap使用注意事项
其实HashMap的使用注意事项在上面讲原理的时候,已经提到了,这里再总结归纳一下:
- 不要多线程使用它,它不是线程安全的,会出问题
- 初始化定义的时候,最好设置一个相对确定的大小,避免频繁扩容,会降低性能
- 如果放入数据比较频繁,它会急剧增大,就应该设置一个恰当的初始大小,并适当降低负载因子,这样以2倍的速度扩容时,能尽可能的降低扩容操作的成本
队列(Queue)
队列是一个先进先出(FIFO, First In First Out)的数据结构,看字面意思也很好理解,一堆东西在那里排队嘛,当然是先来的先办理了,后来的人无特殊情况,往后面排,不得插队。但凡事也有例外,比如我们在火车站、银行可以看到“军人依法优先”。
队列简介
Java中的队列还是很多的,简单地讲,有两大类:阻塞队列和非阻塞队列,按数据存储和访问形式,可以分为单端队列和双端队列:
- 阻塞队列,从队列中取出元素,或放入元素时,只要没有放进去或取出来,就阻塞在那里一直等,直到成功为止(也可以设置超时,比如最多等60秒)
- 非阻塞队列,从队列中取出元素或放入元素时,无论成功失败,会立即返回
Java中队列相关类、接口继承和实现关系图:

在上面这张图中:
- List不用说了,是个通用的接口,它定义了一个容器,只要能放里放东西就是了,它继承自Collection接口,很容易体现这一点
- LinkedList 链表,元素不连续保存,但是每个元素中保存了相邻的元素的地址,可以实现从这个找到那个,松散保存的数据结构
- Dequeue 双端队列,就是既可以从队列头部取数据,也可以从队列尾部取数据
- Queue 队列接口,它定义了队列操作的基本方法,比如入队、出队、查找、删除等,继承自Collection
- PriorityQueue 优先级队列,数据入队的时候,可以指定优先级,这样就能实现队列中优先级高的先取,优先级低的后取,但是要注意:如果优先级的数据源源不断,就有可能导致优先级低的数据永远也没有机会被取到
- BlockingQueue 阻塞队列,是个接口
- DelayQueue 延迟队列
- PriorityBlockingQueue 优先级阻塞队列,这个对于处理生产者消费者的业务模型是非常有用的
- LinkedBlockingQueue 链表式阻塞队列,线程池经常使用这个
队列应用
JDK的队列封装的非常好,几乎所有队列的使用方法都是一样的:
- add 增加一个元索,如果队列已满,则抛出一个IIIegaISlabEepeplian异常
- remove 移除并返回队列头部的元素,如果队列为空,则抛出一个NoSuchElementException异常
- element 返回队列头部的元素,如果队列为空,则抛出一个NoSuchElementException异常
- offer 添加一个元素并返回true,如果队列已满,则返回false
- poll 移除并返问队列头部的元素,如果队列为空,则返回null
- peek 返回队列头部的元素,如果队列为空,则返回null
- put 添加一个元素,如果队列满,则阻塞
- take 移除并返回队列头部的元素,如果队列为空,则阻塞
剩下的事情就很简单了,看代码:
import java.util.LinkedList;
import java.util.Queue;
public class QueueExample {
public static void main(String[] args)
{
Queue<Integer> q = new LinkedList<>();
// 添加元素 {0, 1, 2, 3, 4} 到队列中
for (int i = 0; i < 5; i++) {
q.add(i);
}
// 打印队列
System.out.println("Elements of queue " + q);
// 删除队列头部元素
Integer removedele = q.remove();
System.out.println("removed element-" + removedele);
System.out.println(q);
// 获得队列头部元素
int head = q.peek();
System.out.println("head of queue-" + head);
// 还可以使用Collection接口中的所有常规的方法,比如size、contains等
int size = q.size();
System.out.println("Size of queue-" + size);
}
}
通过队列可以很容易的实现一个生产者消费者模型,这种模型在实际业务开发中非常常用,这里讲一个典型地需求:
用户提交发布文章,在页面上展示的同时,我们需要开一个文章分析服务,它做另外一件事情,就是统计分析它的数字、文章质量、是否抄袭等。传统的做法是用户提交的数据正常进入数据库,然后我们开另外一个服务去数据库中检查它们,但是这种做法有一个问题无解:文章数量越来越大,每次服务开始执行都要从数据库中逐条寻找和处理,很麻烦,效率很低,此时肯定有人想到另外一种方案,数据库中增加一个标记字段,只要该文章被分析过了,设置一个标记,文章分析服务查数据库的时候只找没有标记的就好了,但这种方案有它的缺点:文章用户是可以修改的,修改时要删除标记,这将文章分析服务和文章发布管理服务的业务逻辑完全混在一起了,不便于维护,没有解耦,另一个问题是当文章数量很多的时候,用这种条件查库的方式会很慢。设计也不够优雅,所以,这不是最优解。
最优解是什么呢?文章管理服务正常走文章的发布、查看、删除等各日常业务,只要用户发布、修改、删除了文章,就将该文章的唯一编号(比如文章ID)发送给文章分析服务,文章分析服务收到该文章编号之后,如果是发布或修改,再走一遍分析,如果是删除,就将分析任务队列中之前保存的文章编号删除,取消该分析任务即可。如此,两大块的业务逻辑就完全剥离开来了,很便于维护,代价小、成本低、效率高。
在上述案例中,文章管理服务就是生产者,文章分析服务就是消费者。生产者将要处理的信息交给消费者,消费者处理和消费这些信息数据。
看代码:
package com.wasu.t.q;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
/**
* 通过队列实现生产者消费者模型
*
* @author lidawei
* @date 2021/11/11 10:35
*/
public class ArrayBlockingQueueExample {
private BlockingQueue<Integer> blockingQueue;
private final Integer[] myArray = {1, 2, 3, 4, 5};
public ArrayBlockingQueueExample() {
blockingQueue = new ArrayBlockingQueue<>(1, true);
(new Thread(new Producer(), "Producer")).start();
(new Thread(new Consumer(), "Consumer")).start();
}
class Producer implements Runnable {
@Override
public void run() {
try {
int counter = 0;
for (int i = 0; i < myArray.length; i++) {
blockingQueue.put(myArray[i]);
if (counter++ < 2) {
Thread.sleep(3000);
}
}
blockingQueue.put(-1);
} catch (InterruptedException e) {
System.err.println(e.getMessage());
}
}
}
class Consumer implements Runnable {
@Override
public void run() {
try {
Integer message = 0;
while (!((message = blockingQueue.take()).equals(-1))) {
System.out.println(Thread.currentThread().getName() + ": " + message);
}
} catch (InterruptedException e) {
System.err.println(e.getMessage());
}
}
}
public static void main(String[] args) {
new ArrayBlockingQueueExample();
}
}
这就是一个最简单的生者产消费者模型,Producer不断地往队列里放数据,Consumer不断地去消费队列中的数据,在这里,消费者队列的任务很简单,就是打印一下得到的数据而已。另外一点要注意的是:如果消费者和生产者是一直要这样合作下去的,就没有上述代码中放入-1这个步骤了,本例是为了避免消费者等待生产者、生产者又等待消费者,最后程序无法退出,所以加了-1这个判断环节。互相等待以致于程序无法正常结束的情况,称之为死锁。
PS:生产者消费者模型非常常用,但是涉及到线程的问题,线程的相关内部,请移步本文线程相关章节学习。
队列实现原理
通过查看源码,我们可以得到如下结论:
- Queue接口与List、Set同一级别,都是继承了Collection接口
- 虽然JDK中的队列既有Collection或List的特性,又有Queue的特性,但是remove、element、offer 、poll、peek这几个接口是属于Queue接口的
- 队列使用堆排序,二叉树,使用数组保存数据,非线程安全
- PriorityBlockingQueue是线程安全的,使用的是ReentrantLock,在入队出队总量等方法加锁,出队无值时候加入Condition队列
- LinkedBlockingQueue,有界,或者默认Integer.MAX_VALUE,使用链表存储节点,Executors.newFixedThreadPool使用此队列,因为Integer.MAX_VALUE太大了,很容易出现OOM,因此现在用的人不多了
系统自带注解
Java中自带10个注解:
- @Override 检查该方法是否是重写方法
- @Deprecated 废弃方法,被这个注解标记的类或者方法(标在方法上更常见一些),应该尽量避免使用,因为这意味着它有可能在未来的版本中被删除
- @SuppressWarnings 抑制警告,有的时候,我们写的代码不完全符合JDK所认为的规范,此时编译时它会提示警告(某些IDE,如IDEA、Eclipse也会直接提示警告信息),可以使用这个注解明确告诉编译器忽略,加在变量上,就忽略变量的不规范警告,加在方法上,就忽略该方法中的所有代码语句的不规范警告,加在类上也是同样的道理,该类范围内的所有不规范的代码的警告都会被忽略
- 还有4个元注解,即:注解的注解,意思是说这4个注解的作用是,当我定义了一个注解,然后要使用这个注解时,它的行为策略如何定义,具体的:
- @Retention 被标注的注解在代码编译时是否保留,如何保留,如果保留下来,代码执行时是可以获取到的,如果没有保留,当然就获取不到了,如果注解定义的时候没有指定此选项,默认是RetentionPolicy.CLASS,是指编译的代码中有注解,但是运行的时候没有,如果指定为RetentionPolicy.RUNTIME,这个注解就能在代码执行的时候获取到
- @Documented 被标注的注解是否包含在用户文档(javadoc)中
- @Target 限定被标注的注解的使用范围,可以用在类上、方法上、变量上等等
- @Inherited 指示被标注的注解是继承自哪个注解
- @SafeVarargs JDK7新增,如果方法或构造器的参数是泛型变量,忽略该警告
- @FunctionalInterface JDK8新增,标识一个函数式接口(具体什么是函数式接口,请移步JDK8新增特性章节)
- @Repeatable JDK8新增,指示一个注解可以在一个标注对象上多次使用(正常情况下是不可以的)
注解的使用
这里我们重点说一下常见注解的使用:
方法重写,这个很简单,如果一个类的方法重写了父类的方法,或者实现了接口的方法,就会有这个@Override注解,代码如下:
interface Friendly {
void greeting();
}
class Baby implements Friendly {
@Override
void greeting() {
System.out.println("Baby greeting!");
}
}
在Baby这个类中,有没有@Override这个注解,对代码的执行没有任何影响,但是有了它,我们可以一眼就看出它是来自接口,对于代码的维护,还是很方便的。
在其他一些地方,是否有注解,对代码的行为有重大影响,以后我们会逐渐学到更多的。
自定义注解
如果系统自带的注解满足不了我们的需求,或者我们想自定义一些特殊功能,可以使用自定义注解,看代码:
@Documented
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface SafeCheck {
}
上述代码标明我的注解会在javadoc用户文档中写明,同时这个SafeCheck注解会用在类上,并且会在代码中保留下来(代码中保留下来的注解在代码执行期间通过反射可以获取到)
注解中还可以设置成员变量,以便于在使用的时候,指定值:
@Documented
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface IpThrottling {
Integer value();
}
class UserService {
@IpThrottling(10)
boolean login() {
System.out.println("login");
}
@IpThrottling(100)
String queryById() {
System.out.println("queryById");
}
}
注解应用最佳实践
在一般的,简单的Java应用程序开发中,其实我们基本上可以认为用不到注解,但是对于复杂的项目,我们很有必要使用注解来巧妙的解决很多问题,如:
- 总共有100个方法作为开放API供别人调用,其中有80个需要验证对方的请求中是否存在网络攻击嫌疑,而另外20个不予处理
- 总共有1000个方法作为开放API,每个API在调用时,将请求参数保存或发送到其他地方(文件、数据库、网络流等等)
- 总共有1000个方法作为开放API,除了登录接口,其中部分接口限速每分钟不超过10次,部分接口限速每分钟不超过100次,
面对这些需求,如果我们在代码中逐个处理,一是处理代码很冗长,二是同样的代码在每个API中都写一遍,很麻烦,也将这些非纯粹的业务代码和业务代码完全糅合在了一起,不便于维护和扩展。
为此,我们做这样的系统设计:
- 定义一个注解,用于IP限流,里面包含一个值,用于指定最大请求次数
- 定义一个业务功能类,这个类提供若干接口供别人使用,该类的各方法上加上注解,同时标注该方法的请求最大次数
- 定义一个代理类,这个类接受别人进来的所有请求,然后转发给相应的具体业务功能类的方法,完成接口调用
- 在代理类调用具体的方法之前,做一个统一的处理逻辑,这个处理逻辑只做一件事情,通过反射获得该方法上的注解,判断它指定的限流是否超出了,如果没超出,正常调用,如果超出了,返回失败
具体什么是反射,紧接着的章节我们会进一步的学习,学习完成之后,我们来写一个相对完整的案例。
反射相关类
Class类
注意,这是个Java中的类,名叫Class,和那个关键字class不是一回事哦。它用于描述Java中的某个类的字段成员名称、方法、构造器,以及该类实现了哪些接口,继承自哪个类等等。对于Java听任何类,我们都可以使用这个Class类得到它的相关信息。
获取某个类的Class对象有三种方式:
1. 类名.class
2. 对象名.getClass()
3. Class.forName(“类的全名”)
通过上述三种方式之一,就可以获得指定类的Class对象,该Class对象中就包含了指定类的所有相关信息。
示例代码:
public class ReflectionTest {
@Test
public void testClass() throws ClassNotFoundException {
Class clazz = null;
//1.通过类名
clazz = Person.class;
//2.通过对象名
//这种方式是用在传进来一个对象,却不知道对象类型的时候使用
Person person = new Person();
clazz = person.getClass();
//上面这个例子的意义不大,因为已经知道person类型是Person类,再这样写就没有必要了
//如果传进来是一个Object类,这种做法就是应该的
Object obj = new Person();
clazz = obj.getClass();
//3.通过全类名(会抛出异常)
//一般框架开发中这种用的比较多,因为配置文件中一般配的都是全类名,通过这种方式可以得到Class实例
String className=" com.wasu.demo.Person";
clazz = Class.forName(className);
//字符串的例子
clazz = String.class;
clazz = "javaTest".getClass();
clazz = Class.forName("java.lang.String");
System.out.println();
}
}
Class类还拥有一些方法,很有用的:
| 方法名称 |
功能说明 |
| static Class forName(String name) |
返回指定类名 name 的 Class 对象 |
| Object newInstance() |
调用缺省构造函数,返回该Class对象的一个实例 |
| Object newInstance(Object []args) |
调用当前格式构造函数,返回该Class对象的一个实例 |
| getName() |
返回此Class对象所表示的实体(类、接口、数组类、基本类型或void)名称 |
| Class getSuperClass() |
返回当前Class对象的父类的Class对象 |
| Class[] getInterfaces() |
获取当前Class对象的接口 |
| ClassLoader getClassLoader() |
返回该类的类加载器 |
| Class getSuperclass() |
返回表示此Class所表示的实体的超类的Class |
Field类
Field是对类中的字段成员的描述,包括类型、名称等。示例代码:
public class ReflectionTest {
@Test
public void testField() throws Exception{
String className = "com.wasu.demo.Person";
Class clazz = Class.forName(className);
//1.获取字段
// 1.1 获取所有字段 -- 字段数组
// 可以获取公用和私有的所有字段,但不能获取父类字段
Field[] fields = clazz.getDeclaredFields();
for(Field field : fields){
System.out.print(" " + field.getName());
}
System.out.println();
// 1.2获取指定字段
Field field = clazz.getDeclaredField("name");
System.out.println(field.getName());
Person person = new Person("ABC", 12);
//2.使用字段
// 2.1获取指定对象的指定字段的值
Object val = field.get(person);
System.out.println(val);
// 2.2设置指定对象的指定对象Field值
field.set(person, "DEF");
System.out.println(person.getName());
// 2.3如果字段是私有的,不管是读值还是写值,都必须先调用setAccessible(true)方法
// 比如Person类中,字段name字段是公用的,age是私有的
field = clazz.getDeclaredField("age");
field.setAccessible(true);
System.out.println(field.get(person));
}
}
Method类
Method是对类中的方法的描述,包括方法名称、形参、返回值等。示例代码:
public class ReflectionTest {
@Test
public void testMethod() throws Exception{
Class clazz = Class.forName("com.wasu.demo.Person");
// 1.获取方法
// 1.1 获取取clazz对应类中的所有方法--方法数组(一)
// 不能获取private方法,且获取从父类继承来的所有方法
Method[] methods = clazz.getMethods();
for(Method method : methods){
System.out.print(" " + method.getName());
}
System.out.println();
//
// 1.2.获取所有方法,包括私有方法 --方法数组(二)
// 所有声明的方法,都可以获取到,且只获取当前类的方法
methods = clazz.getDeclaredMethods();
for(Method method : methods){
System.out.print(" " + method.getName());
}
System.out.println();
//
// 1.3.获取指定的方法
// 需要参数名称和参数列表,无参则不需要写
// 对于方法public void setName(String name) { }
// 如果方法不存在,返回返回null
Method method = clazz.getDeclaredMethod("setName", String.class);
System.out.println(method);
// 而对于方法public void setAge(int age) { }
method = clazz.getDeclaredMethod("setAge", Integer.class);
System.out.println(method);
// 这样写是获取不到的,如果方法的参数类型是int型
// 如果方法用于反射,那么要么int类型写成Integer: public void setAge(Integer age) { }
// 要么获取方法的参数写成int.class
//
// 2.执行方法
// invoke第一个参数表示执行哪个对象的方法,剩下的参数是执行方法时需要传入的参数
Object obje = clazz.newInstance();
method.invoke(obje,2);
//如果一个方法是私有方法,第三步是可以获取到的,但是这一步却不能执行
//私有方法的执行,必须在调用invoke之前加上一句method.setAccessible(true); }
}
ClassLoader
ClassLoader其实我们在前面讲类加载机制的时候已经提到了,它就是类加载器。所有Java应用中的类,都是被java.lang.ClassLoader类的一系列子类加载的,因此想要动态加载类,也就必须使用java.lang.ClassLoader的子类。
一个类被加载时,它所引用的其他类也会被同时加载,这是一个递归的过程,但是要注意的是,只有有引用关系的类才会被加载。
此外,类在加载的过程中,还会对检查情况进行确认:检查该类是否已经被加载,如果没有加载,则首先调用父类加载器加载,一层一层往上走,直到Bootstrap ClassLoader也不能加载,再逐级返回到本级类加载器,此时判断如果父类加载器不能加载这个类,则尝试加载这个类。这就是双亲委派机制。
这种情况下,可以通过类加载器加载当前Java应用中的src目录下的所有类,也可以加载CLASSPATH环境变量所指向的目录中的类(包括配置CLASSPATH的时候指定的.这个当前目录)。
public class ReflectionTest {
@Test
public void testClassLoader() throws FileNotFoundException{
//src目录下,直接加载
InputStream in1 = null;
in1 = this.getClass().getClassLoader().getResourceAsStream("test1.txt");
//放在内部文件夹,要写全路径
InputStream in2 = null;
in2 = this.getClass().getClassLoader().getResourceAsStream("com/wasu/reflect/demo/test.txt");
}
}
反射功能实践
上面讲述了反射功能的用法,也介绍了通过ClassLoader动态加载类。看到这里,有同学可能会有疑问,我写代码的时候,都是预先定义好类,再new它的实例,然后操作的,通过反射动态的获取类的字段、方法、初始化它的实例,这些东西都有啥用呢?其实啊,用处大了去了,我在这里给大家列举几个非常常用的应用场景:
- 数据校验,这个应用场景是这样的,当你给开发若干个接口(API)给别人使用的时候,对于别人调你接口给你数据的时候,你肯定是要校验一下的,必须手机号是不是11位数字、姓名是不是中文、金额是不是负数、工资是不是超过20亿了(至少目前我挣不了这么多钱)等等。这个时候有一个问题,如果你在每个接口中都进行校验,那是非常麻烦的,每写一个接口,就要写一堆if…else,代码冗余、丑陋不堪、维护困难。这个时候,你将接口的形参数定义好一个Java类,然后在这个形参Java类的字段上加上自己定义的注解,标示是否允许为空、最大值、最小值等等之类的校验规则,然后再定义一个代理类,所有请求都先进入代理类,代理类通过反射获得所有数据,同时获得字段上的注解,依据这些规则判断一下数据有没有问题,没问题再赋值给目标API的形参,然后再调用目标API的方法。这就是一个非常通用的、优雅的实现,事实上Java领域最著名的Spring框架的数据校验,就是这种实现思想。
- 安全校验,安全校验我们通常要做两件事情,一是记录请求对象的IP并查验它的次数,二是验证请求参数是否合乎已方安全规范。这些东西都是通用的,如果我们做多个项目的时候,不同的项目中逐个实现一遍,很麻烦,同样是通过反射机制,将对方发送过来的数据解构,然后做一些安全处理,合规放行,不合规拒绝,这种做法可以完全避免对业务代码的冲击,使得编写业务代码的人完全不必担心安全问题。
- 名单机制,在许多业务场景,我们会有黑名单、白名单、灰名单等等机制,这是为了针对特定场景的用户做特殊处理的,比如天天无效登录次数很多的用户,我将会强制要求它修改密码,否则不能进入系统。如果我们将这些功能都写在业务代码中,它就无法灵活扩展了,每次修改都会先检查业务代码是否受到冲击和影响,很麻烦,我们可以对名单机制定义一个接口,然后调用代码的时候,通过接口和反射手段,动态决定走什么名单,此后,如果名单机制有增减,代码不必做任何变动,灵活性和扩展性都极好。
- 插件化,插件化一般场景用不着,但是一旦要用,功能却非常强大,当我们为客户开发一款软件系统的时候,我们通常不能保证100%的需求覆盖度,这种情况下,我们对一些需求进行归纳总结,抽象成一些通用的方法和接口,然后预留在代码中,以后当需求有变动的时候,只要还在当初定义的规则之下,我们不必修改原有的代码,只需要在原有规则之下新写一套Java类,打成Jar包放在CLASSPATH下,然后通过反射机制让它动态地加载和执行就可以了,这就相当于原来的应用程序预留了插件机制,新开发的插件只要放到指定的位置(甚至可以通过网络字段流传过去),就可以实现动态扩展应用程序的功能。
- 代码复用,代码复用的问题其实在介绍前面几个应用场景的时候已经提到了,很常见的,我在多个地方都要校验一个整数的最大值和最小值,到处写很多的if…else明显不合理,此时我只需要定义一个自定义的注解,然后设置该注解有两个成员变量
min和max,用于指定最大值和最小值,然后将该注解应用到被校验的类上面,然后写一个通用的校验方法即可解决问题。
JDK7及以前的日期与时间
Date类
示例代码:
// 创建一个Date类型的实例
java.util.Date date = new java.util.Date();
// 通过date实例获得时间戳
long time = date.getTime();
// 获得一个时间戳
long now = System.currentTimeMillis();
// 通过时间戳获得日期时间对象Date实例
java.util.Date date1 = new java.util.Date(now);
// 日期时间格式化(日期时间对象转为字符串),最常见的格式就三种:yyyy-MM-dd hh:mm:ss、yyyy-MM-dd、hh:mm:ss
// 这个格式很好理解:y是年(year)、M是月(month)、d是日(Day)、h是小时(hour)、m是分钟(minute)、s是秒(second)
// 所谓日期时间六要素中,m出现了两次,日比分大,所以日是大m,分是小m。
SimpleDateFormat ft = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
String dateStr = ft.format(new java.util.Date());
// 将描述日期时间的字符串转换为日期对象(前提是格式正确,否则会出现异常)
java.util.Date parsedDate = ft.parse(dateStr)
这里的时间戳,指的是UNIX时间戳,UNIX时间戳是指从1970年1月1日(UTC/GMT的午夜)开始到当前时间所经过的秒数,不考虑闰秒。Java中的System.currentTimeMillis()得到的是一个包含毫秒值的UNIX时间戳,许多时候也用它来记录一些数据的时间信息。但是请注意:这个方法返回的数据是long类型的,不是int类型。
对日期进行比较也很常见:
// java.util.Date类实现了java.lang.Comparable接口,所以你可以对java.util.Date实例进行比较
java.util.Date date1 = new java.util.Date();
java.util.Date date2 = new java.util.Date();
// 比较结果遵循Comparable接口的定义:
// comparison 小于0,date1比date2晚
// comparison 等于于0,date1比date2相同
// comparison 大于0,date1比date2早
int comparison = date1.compareTo(date2);
还可以使用Java自带的比较方法:
java.util.Date date1 = new java.util.Date();
java.util.Date date2 = new java.util.Date();
boolean isBefore = date1.before(date2);
boolean isAfter = date1.after (date2);
注意 : 不要使用JDK7自带的Date类型去获得年、月、日、时、分、秒的具体值,这是个垃圾,几乎不能用。并且它们和日期格式化的类SimpleDateFormat都不是线程安全的,即:不要使用多个线程同时操作一个实例。
Calender类
Calendar类的功能要比Date类强大很多,可以方便的进行日期的计算,获取日期中的信息时考虑了时区等问题。而且在实现方式上也比Date类要复杂一些。
Calendar c = Calendar.getInstance();//默认是当前日期
// 设置Calendar对象的时间为2009年6月12日,月份要减1(不知道当初设计JDK的人脑袋里装的是什么,内部的实现中,月份竟然是从0开始的,所以,5就是6月份,所以为了便于观察,写成6-1)
c.set(2009, 6 - 1, 12);
// 或者用这种方式:
c1.set(2009, Calendar.JULY, 12);
// 从一个Calendar实例对象中获得年、月、日、时、分、秒
// 获得年份
int year = c1.get(Calendar.YEAR);
// 获得月份,要+1
int month = c1.get(Calendar.MONTH) + 1;
// 获得日
int date = c1.get(Calendar.DATE);
// 获得小时
int hour = c1.get(Calendar.HOUR_OF_DAY);
// 获得分钟
int minute = c1.get(Calendar.MINUTE);
// 获得秒
int second = c1.get(Calendar.SECOND);
// 获得星期几(注意(这个与Date类是不同的):1代表星期日、2代表星期一、3代表星期二,以此类推)
int weekDay = c1.get(Calendar.DAY_OF_WEEK);
GregorianCalendar类
Calendar类实现了公历日历,它是是Calendar类的一个具体实现。
package com.wasu.t.dt;
import java.util.Calendar;
import java.util.GregorianCalendar;
/**
* GregorianCalendar日期类功能示例
*
* @author lidawei
* @date 2021/11/16 14:09
*/
public class GregorianCalendarDemo {
public static void main(String[] args) {
final String[] months = {
"Jan", "Feb", "Mar", "Apr",
"May", "Jun", "Jul", "Aug",
"Sep", "Oct", "Nov", "Dec"};
int year;
// 初始化 Gregorian 日历
// 使用当前时间和日期
// 默认为本地时间和时区
GregorianCalendar gcalendar = new GregorianCalendar();
// 显示当前时间和日期的信息
System.out.print("Date: ");
System.out.print(months[gcalendar.get(Calendar.MONTH)]);
System.out.print(" " + gcalendar.get(Calendar.DATE) + " ");
System.out.println(year = gcalendar.get(Calendar.YEAR));
System.out.print("Time: ");
System.out.print(gcalendar.get(Calendar.HOUR) + ":");
System.out.print(gcalendar.get(Calendar.MINUTE) + ":");
System.out.println(gcalendar.get(Calendar.SECOND));
// 测试当前年份是否为闰年
if (gcalendar.isLeapYear(year)) {
System.out.println("当前年份是闰年");
} else {
System.out.println("当前年份不是闰年");
}
}
}
输出:
Date: Nov 16 2021
Time: 2:10:49
当前年份不是闰年
!> JDK7及之前的版本,日期时间相关的类非常难用,如果在业务中非常常见的类似于计算n秒之前、n小时之前、n天之前,还需要自己处理更高位的进位(类似于n小时之前时,如果n大于60,就要按24进制去处理天),或者判断今天是今年中的第几天、两个日期中间相隔几天、几小时等等,非常麻烦,极其难用,所以有人开发了功能更强大的类库,名叫Joda-Time,有兴趣的同学们可以参阅其他文章,如果你使用的是JDK7及之前的版本,推荐使用该类库。
JDK8的日期与时间
JDK8的日期时间类好用多了,并且增加了一个线程安全的、用于格式化日期时间的类DateTimeFormatter。新的时间及日期API位于 java.time 包中,下面是一些关键类:
- Instant:代表的是时间戳
- LocalDate:不包含具体时间的日期
- LocalTime:不含日期的时间
- LocalDateTime:包含了日期及时间
LocalDate nowDate = LocalDate.now();
System.out.println("今天的日期:" + nowDate);//今天的日期:2018-09-06
int year = nowDate.getYear();//年:一般用这个方法获取年
System.out.println("year:" + year);//year:2018
int month = nowDate.getMonthValue();//月:一般用这个方法获取月
System.out.println("month:" + month);//month:9
int day = nowDate.getDayOfMonth();//日:当月的第几天,一般用这个方法获取日
System.out.println("day:" + day);//day:6
int dayOfYear = nowDate.getDayOfYear();//日:当年的第几天
System.out.println("dayOfYear:" + dayOfYear);//dayOfYear:249
//星期
System.out.println(nowDate.getDayOfWeek());//THURSDAY
System.out.println(nowDate.getDayOfWeek().getValue());//4
//月份
System.out.println(nowDate.getMonth());//SEPTEMBER
System.out.println(nowDate.getMonth().getValue());//9
LocalDateTime nowDateTime = LocalDateTime.now();
System.out.println("今天是:" + nowDateTime);//今天是:2018-09-06T15:33:56.750
System.out.println(nowDateTime.getYear());//年
System.out.println(nowDateTime.getMonthValue());//月
System.out.println(nowDateTime.getDayOfMonth());//日
System.out.println(nowDateTime.getHour());//时
System.out.println(nowDateTime.getMinute());//分
System.out.println(nowDateTime.getSecond());//秒
System.out.println(nowDateTime.getNano());//纳秒
//日:当年的第几天
System.out.println("dayOfYear:" + nowDateTime.getDayOfYear());//dayOfYear:249
//星期
System.out.println(nowDateTime.getDayOfWeek());//THURSDAY
System.out.println(nowDateTime.getDayOfWeek().getValue());//4
//月份
System.out.println(nowDateTime.getMonth());//SEPTEMBER
System.out.println(nowDateTime.getMonth().getValue());//9
LocalTime也很简单,就不一一演示了。
我们在这里再列举几个实践中非常常见的应用场景:
计算时间差方式一:
LocalDate startDate = LocalDate.of(1993, Month.OCTOBER, 19);
System.out.println("开始时间 : " + startDate);
LocalDate endDate = LocalDate.of(2017, Month.JUNE, 16);
System.out.println("结束时间 : " + endDate);
long daysDiff = ChronoUnit.DAYS.between(startDate, endDate);
System.out.println("两天之间的差在天数 : " + daysDiff);
计算时间差方式二:
Instant inst1 = Instant.now();
Instant inst2 = inst1.plus(Duration.ofSeconds(10));
System.out.println("Difference : " + Duration.between(inst1, inst2));
Instant inst3 = inst1.plus(Duration.ofSeconds(100));
System.out.println("Difference : " + Duration.between(inst1, inst3));
System.out.println("Difference in milliseconds : " + Duration.between(inst1, inst2).toMillis());
时间增减
//三天后
LocalDate afterThreeDays = LocalDate.now().plusDays(3);
//三天前
LocalDate threeDaysAgo = LocalDate.now().minusDays(3);
时区信息
// 无时区信息的时间
Instant instant = Instant.now();
System.out.println(instant);
// 获取当前时区的时间
System.out.println(instant.atZone(ZoneId.systemDefault()));
获取时间戳
// 当前时间戳:单位为秒
System.out.println(instant.getEpochSecond());
// 当前时间戳:单位为毫秒
System.out.println(instant.toEpochMilli());
判断闰年
// 判断是否为闰年
bool isLeapYear = today.getYear() + " is leap year:" + LocalDate.now().isLeapYear();
System.out.println(isLeapYear);
日期时间格式化:
LocalDate localDate = LocalDate.now();
// 使用几个内置的格式
System.out.println("ISO_DATE: " + localDate.format(DateTimeFormatter.ISO_DATE));
System.out.println("BASIC_ISO_DATE: " + localDate.format(DateTimeFormatter.BASIC_ISO_DATE));
System.out.println("ISO_WEEK_DATE: " + localDate.format(DateTimeFormatter.ISO_WEEK_DATE));
System.out.println("ISO_ORDINAL_DATE: " + localDate.format(DateTimeFormatter.ISO_ORDINAL_DATE));
LocalTime localTime = LocalTime.now();
System.out.println(localTime);
System.out.println("ISO_TIME: " + localTime.format(DateTimeFormatter.ISO_TIME));
System.out.println("HH:mm:ss: " + localTime.format(DateTimeFormatter.ofPattern("HH:mm:ss")));
// 自己定义格式
System.out.println("yyyy/MM/dd: " + localDate.format(DateTimeFormatter.ofPattern("yyyy/MM/dd")));
文件I/O
文件I/O也就是文件读写,也是Java中比较常见的操作。Java中读写文件的方法有很多种,我们这里学习比较常用的。
文本文件读写
按行读:
public class ReadTextLineDemo {
public statid void main(String[] args) {
File file = new File("/test.txt");
BufferedReader reader = null;
try {
System.out.println("以行为单位读取文件内容,一次读一整行:");
reader = new BufferedReader(new FileReader(file));
String tempString = null;
int line = 1;
// 一次读入一行,直到读入null为文件结束
while ((tempString = reader.readLine()) != null) {
// 显示行号
System.out.println("line " + line + ": " + tempString);
line++;
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭文件的操作是必须的
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
写入文本文件:
import java.io.*;
public class Main {
public static void main(String[] args) {
try {
BufferedWriter out = new BufferedWriter(new FileWriter("runoob.txt"));
out.write("菜鸟教程");
out.close();
System.out.println("文件创建成功!");
} catch (IOException e) {
e.printStackTrace();
}
}
}
二进制文件读写
package com.wasu.t.io;
import java.io.*;
/**
* 将一段数据写入二进制文件中,然后再读出来
*
* @author lidawei
* @date 2021/11/17 14:31
*/
public class BinFileReadWriteDemo {
public static void main(String[] args) {
byte[] b = {1, 2};
try {
DataOutputStream os = new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream("/tmp/data.bin")));
System.out.println(b[0] + " " + b[1]);
os.write(b);
os.flush();
os.close();
} catch (IOException e) {
e.printStackTrace();
}
//读取data.bin文件中的数据
try {
DataInputStream is = new DataInputStream(
new BufferedInputStream(
new FileInputStream("/tmp/data.bin")));
byte[] c = new byte[2];
is.read(c);
is.close();
System.out.println(b[0] + " " + b[1]);
} catch (IOException e) {
e.printStackTrace();
}
}
}
文件读写高级API
随机读取文件内容:
import java.io.*;
public class Main {
public static void main(String[] args) {
RandomAccessFile randomFile = null;
try {
System.out.println("随机读取一段文件内容:");
// 打开一个随机访问文件流,按只读方式
randomFile = new RandomAccessFile("filename.bin", "r");
// 文件长度,字节数
long fileLength = randomFile.length();
// 读文件的起始位置
int beginIndex = (fileLength > 4) ? 4 : 0;
// 将读文件的开始位置移到beginIndex位置。
randomFile.seek(beginIndex);
byte[] bytes = new byte[10];
int byteread = 0;
// 一次读10个字节,如果文件内容不足10个字节,则读剩下的字节。
// 将一次读取的字节数赋给byteread
while ((byteread = randomFile.read(bytes)) != -1) {
System.out.write(bytes, 0, byteread);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (randomFile != null) {
try {
randomFile.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
向文件末尾追加内容:
import java.io.*;
public class Main {
public static void main(String[] args) {
try {
// 打开一个随机访问文件流,按读写方式
RandomAccessFile randomFile = new RandomAccessFile("filename.bin", "rw");
// 文件长度,字节数
long fileLength = randomFile.length();
// 将写文件指针移到文件尾。
randomFile.seek(fileLength);
randomFile.writeBytes("this content will be append to the end of file");
randomFile.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
文件操作相关的API还有很多,尤其是NIO接口,可以实现对大文件的操作的同时保证性能,有兴趣的同学可以在觉得Java基础掌握的差不多的情况下进一步学习研究。
无论文件的实际格式是什么,以二进制方式读写文件,能够始终保证文件的结果的正确性,因为任何数据最终都是二进制形式的,但是如果以文本形式读写文件,对于正常的文本文件自然没问题,但是如果对于二进制文件(如图片、视频)使用文本文件的方法去读写,结果是不可预料的。
网络I/O
GET请求
package com.wasu.t.net;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
/**
* 发送GET请求
*
* @author lidawei
* @date 2021/11/17 15:10
*/
public class GetRequestDemo {
public static void main(String[] args) {
try {
StringBuilder stringBuilder = new StringBuilder();
URL url = new URL("https://www.11ms.cn");
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
//链接超时
urlConnection.setConnectTimeout(5 * 1000);
//返回数据超时
urlConnection.setReadTimeout(5 * 1000);
// 等于200请求成功,其他都是失败
if (urlConnection.getResponseCode() == 200) {
//获得读取流写入
InputStream inputStream = urlConnection.getInputStream();
byte[] bytes = new byte[1024];
int len = 0;
while ((len = inputStream.read(bytes)) != -1) {
stringBuilder.append(new String(bytes, 0, len));
}
// 读取响应后,关闭流,防止资源泄漏
inputStream.close();
}
// 如果这个网络连接后面不用了,就断开连接,及时释放资源
urlConnection.disconnect();
System.out.println(stringBuilder);
} catch (IOException e) {
e.printStackTrace();
}
}
}
POST请求
package com.wasu.t.net;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.Map;
/**
* 功能描述
*
* @author lidawei
* @date 2021/11/17 15:16
*/
public class PostRequestDemo {
public static void main(String[] args) {
StringBuilder stringBuilder = new StringBuilder();
try {
URL url = new URL("http://localhost:9191/login");
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
urlConnection.setConnectTimeout(5 * 1000);
urlConnection.setReadTimeout(5 * 1000);
//设置请求方式,默认是GET,现在要发POST请求,就设置为大写的POST
urlConnection.setRequestMethod("POST");
//设置允许输出,允许向服务器提交数据
urlConnection.setDoOutput(true);
//获得输出流写数据 "&page=1"
//请求参数放到请求体
OutputStream outputStream = urlConnection.getOutputStream();
StringBuilder body = new StringBuilder();
// 拼接一个JSON发给服务器,正式开发期间,通常不会这么操作,
// 而是要将发送的数据定义成一个Java类或Map,然后使用JSON框架序列化成字节串发送出去
body.append("{")
.append("\"username\"").append("\"u1\"")
.append("\"password\"").append("\"p1\"")
.append("}");
outputStream.write(body.toString().getBytes(StandardCharsets.UTF_8));
if (urlConnection.getResponseCode() == 200) {
InputStream inputStream = urlConnection.getInputStream();
byte[] bytes = new byte[1024];
int len = 0;
while ((len = inputStream.read(bytes)) != -1) {
stringBuilder.append(new String(bytes, 0, len));
}
inputStream.close();
} else {
System.out.println(urlConnection.getResponseCode());
}
outputStream.close();
urlConnection.disconnect();
System.out.println(stringBuilder);
} catch (IOException e) {
e.printStackTrace();
}
}
}
第三方框架
使用JDK自带的方法去发送网络请求,发送数据开一个流,响应数据开一个流,请求再控制一遍,其实很麻烦,并不是非常好用。所以才有了各种优秀的第三方框架,典型的是两个,一个是Apache软件基金会开源的老牌HttpClient,还有一个是最几年的后起之秀OkHttp。有兴趣的同学们可以研究一下,查查相关文档学一学怎么使用。
NIO
NIO(Non-blocking I/O,在Java领域,也称为New I/O),是一种同步非阻塞的I/O模型,也是I/O多路复用的基础,已经被越来越多地应用到大型应用服务器,成为解决高并发与大量连接、I/O处理问题的有效方式。自JDK 1.4起引入。
相对于NIO,还有传统的BIO,也就是阻塞型的I/O模型,Java的Web开发领域的著名容器产品Tomcat就使用了这些技术,Tomcat7之前的版本是BIO,Tomcat8及之后的版本已经默认使用NIO。
非阻塞,就是访问一个资源时,会立即返回,资源操作完成之后,再触发回调。性能高,但是软件代码比较复杂。
阻塞,就是访问一个资源时,在访问点上一直等待,直到访问操作成功返回。代码相对简单,不会发生回调。
NIO又分为文件NIO和网络NIO,它们是高效地访问文件或进行网络通信的技术,因为涉及到线程的相关技术。所以本文先只做了些简单的基本介绍。
静态代理
先定义一个User的操作接口:
public interface UserService {
void save(Integer userId, String mobile);
}
再定义一个目标对象:
public class UserServiceImpl implements UserService {
@Override
public void save(Integer userId, String mobile) {
System.out.println("用户信息已保存");
}
}
代理对象:
public class UserServiceProxy implements UserService {
private UserService userService;
public UserServiceProxy(UserService userService) {
this.userService = userService;
}
@Override
public void save(Integer userId, String mobile) {
System.out.println("开启MySQL的事务");
try {
this.userService.save(userId, mobile);
System.out.println("提交事务");
} catch (Exception e) {
System.out.println("回滚事务");
e.printStackTrace();
}
}
}
测试调用:
public class App {
public static void main(String[] args) {
UserService target = new UserServiceImpl();
UserServiceProxy proxy = new UserServiceProxy(target);
proxy.save(1, "13012345678");
}
}
上述这种代理方式,是在软件编码阶段就定义好了代理关系,所以称之为静态代理。它能够实现对目标不修改的情况下,增强它的功能(比如本例中的数据库事务),但是它也有一个很明显的缺点,就是当我的操作比较多,类比较多的时候,每次接口的变动都涉及到很多改动,随着业务的复杂度的上升,类也会越来越多,维护会越来越困难。
动态代理
动态代理和静态代理的核心思想是一样的:不直接访问目标对象,而是通过代理对方去访问。但是相对于静态代理来说,最大的区别就在于它是在运行时动态生成的,而不是编码阶段就定义的。所以,相对于静态代理的一个一个去修改某个接口下面的所有实现类,动态代理的优势是非常明显的,它可以使用一套统一的方法处理掉所有的非业务逻辑事项(即,处理掉所有被代理对象本身的业务逻辑之外的事情,比如安全、日志、计时、身份验证等等)。
软件编程领域有一个应用很广泛的概念,叫AOP(Aspect Oriented Programming,面向切面编程),这是一种编程思想,而动态代理就是这种编程思想的一种具体实现方式。
说动态代理之前,我们先说一下java.lang.reflect.InvocationHandler这个接口,这个接口只有一个方法:
package java.lang.reflect;
public interface InvocationHandler {
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable;
}
具体的做法是,定义一个代理类,实现上述java.lang.reflect.InvocationHandler这个接口,再通过类java.lang.reflect.Proxy生成一个代理对象,就可以通过代理对象实现对目标对象的调用了,代码如下:
package com.wasu.t.dynamic_proxy;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
/**
* 动态代理功能示例
*
* @author lidawei
* @date 2021/11/18 16:35
*/
public class DynamicProxyDemo {
private interface UserService {
void save(String name);
}
private static class UserServiceImpl implements UserService {
@Override
public void save(String name) {
System.out.println("用户" + name + "已保存");
}
}
private static class UserProxy implements InvocationHandler {
private UserService userService;
public UserProxy(UserService userService) {
this.userService = userService;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("开启事务");
Object returnValue = null;
try {
// 执行目标对象方法
returnValue = method.invoke(userService, args);
System.out.println("提交事务");
} catch (Exception e) {
System.out.println("回滚事务");
e.printStackTrace();
}
return returnValue;
}
}
public static void main(String[] args) {
UserService userService = new UserServiceImpl();
System.out.println(userService.getClass());
UserService userServiceProxy = (UserService)Proxy.newProxyInstance(
userService.getClass().getClassLoader(),
userService.getClass().getInterfaces(),
new UserProxy(userService)
);
System.out.println(userServiceProxy.getClass());
userServiceProxy.save("demo");
}
}
运行此代码,输出:
class com.wasu.t.dynamic_proxy.DynamicProxyDemo$UserServiceImpl
class com.wasu.t.dynamic_proxy.$Proxy0
开启事务
用户demo已保存
提交事务
上面就是JDK的动态代理的用法,看到这里,相信有许多同学会有疑问了,这看上去和静态代理也没什么区别啊,为什么还要弄的这么复杂呢?其实不然,我们假设这样一个应用场景:你在包com.example.api中定义了一个类ApiA,那么你用上述代码去做一个统一的方法调用耗时统计,这没问题,也不复杂,但是在实践中,我们为了让代码和架构更加具有灵活性和扩展性,还有这样的情况:当我在这个代码包com.example.api中又新增了一个类ApiB的时候,我不应该也不需要去修改我的方法调用耗时统计机制,就能让方法耗时统计机制自动覆盖到新增的类而不是还要去修改耗时统计机制。要实现这个,要怎么做呢?请看下面的代码:
package com.wasu.t.dynamic_proxy;
import java.lang.reflect.*;
import java.time.Duration;
import java.time.LocalDateTime;
import java.util.Random;
/**
* 动态代理与动态扩展示例代码
*
* @author lidawei
* @date 2021/11/18 16:35
*/
public class DynamicProxyDemo2 {
public static class ApiA {
public void doIt() throws InterruptedException {
// 模拟方法执行耗时
Thread.sleep(new Random().nextInt(1000));
System.out.println("ApiA doIt method done");
}
}
public static class ApiB {
public void doIt() throws InterruptedException {
// 模拟方法执行耗时
Thread.sleep(new Random().nextInt(1000));
System.out.println("ApiB doIt method done");
}
}
private static class MethodCostProxy implements InvocationHandler {
private final Object target;
public MethodCostProxy(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
LocalDateTime start = LocalDateTime.now();
// 执行目标对象方法
Object returnValue = method.invoke(target, args);;
System.out.println("目标方法" + target.getClass().getName() + "." + method.getName() + "耗时:" + Duration.between(start, LocalDateTime.now()));
return returnValue;
}
}
public static void main(String[] args) throws Throwable {
Class<?>[] declaredClasses = DynamicProxyDemo2.class.getDeclaredClasses();
for (Class<?> declaredClass : declaredClasses) {
// 这里忽略掉我自己定义的这个类
if (declaredClass.getName().endsWith("MethodCostProxy")) {
continue;
}
Object api = declaredClass.newInstance();
MethodCostProxy costProxy = new MethodCostProxy(api);
Object proxy = Proxy.newProxyInstance(
declaredClass.getClassLoader(),
declaredClass.getInterfaces(),
costProxy
);
Method[] declaredMethods = api.getClass().getDeclaredMethods();
for (Method declaredMethod : declaredMethods) {
costProxy.invoke(proxy, declaredMethod, new Object[]{});
}
}
}
}
运行上述代码得到以下输出:
ApiB doIt method done
目标方法com.wasu.t.dynamic_proxy.DynamicProxyDemo2$ApiB.doIt耗时:PT0.542S
ApiA doIt method done
目标方法com.wasu.t.dynamic_proxy.DynamicProxyDemo2$ApiA.doIt耗时:PT0.931S
在这段代码中,我为了演示方便,把ApiA和ApiB两个类都放在了我的测试类DynamicProxyDemo2中,让它成为内部类。重点讲解:
- MethodCostProxy类中的代理对象target,改为Object,这样就能代理任何类了
- main方法第一行,我是通过反射的方法获得这个类的内部类,然后遍历处理,如果是我自己的代理类MethodCostProxy,就忽略它,那么,现在这个DynamicProxyDemo2中有ApiA和ApiB,都能成功调用,在此基础上,我如果增加一个ApiC,或者我在ApiB类下增加了一个方法,此时其他地方统统都不用改,就能自动记录该类的方法耗时,请看代码:
package com.wasu.t.dynamic_proxy;
import java.lang.reflect.*;
import java.time.Duration;
import java.time.LocalDateTime;
import java.util.Random;
/**
* 动态代理与动态扩展示例代码
*
* @author lidawei
* @date 2021/11/18 16:35
*/
public class DynamicProxyDemo2 {
public static class ApiA {
public void doIt() throws InterruptedException {
Thread.sleep(new Random().nextInt(1000));
System.out.println("ApiA doIt method done");
}
}
public static class ApiB {
public void doIt() throws InterruptedException {
Thread.sleep(new Random().nextInt(1000));
System.out.println("ApiB doIt method done");
}
public void doIt2() throws InterruptedException {
Thread.sleep(new Random().nextInt(1000));
System.out.println("ApiB doIt2 method done");
}
}
public static class ApiC {
public void doIt() throws InterruptedException {
Thread.sleep(new Random().nextInt(1000));
System.out.println("ApiC doIt method done");
}
}
private static class MethodCostProxy implements InvocationHandler {
private final Object target;
public MethodCostProxy(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
LocalDateTime start = LocalDateTime.now();
// 执行目标对象方法
Object returnValue = method.invoke(target, args);;
System.out.println("目标方法" + target.getClass().getName() + "." + method.getName() + "耗时:" + Duration.between(start, LocalDateTime.now()));
return returnValue;
}
}
public static void main(String[] args) throws Throwable {
Class<?>[] declaredClasses = DynamicProxyDemo2.class.getDeclaredClasses();
for (Class<?> declaredClass : declaredClasses) {
// 这里忽略掉我自己定义的这个类
if (declaredClass.getName().endsWith("MethodCostProxy")) {
continue;
}
Object api = declaredClass.newInstance();
MethodCostProxy costProxy = new MethodCostProxy(api);
Object proxy = Proxy.newProxyInstance(
declaredClass.getClassLoader(),
declaredClass.getInterfaces(),
costProxy
);
Method[] declaredMethods = api.getClass().getDeclaredMethods();
for (Method declaredMethod : declaredMethods) {
costProxy.invoke(proxy, declaredMethod, new Object[]{});
}
}
}
}
执行代码输出:
ApiC doIt method done
目标方法com.wasu.t.dynamic_proxy.DynamicProxyDemo2$ApiC.doIt耗时:PT0.472S
ApiB doIt method done
目标方法com.wasu.t.dynamic_proxy.DynamicProxyDemo2$ApiB.doIt耗时:PT0.099S
ApiB doIt2 method done
目标方法com.wasu.t.dynamic_proxy.DynamicProxyDemo2$ApiB.doIt2耗时:PT0.429S
ApiA doIt method done
目标方法com.wasu.t.dynamic_proxy.DynamicProxyDemo2$ApiA.doIt耗时:PT0.535S
PS: 如果在此基础上,我把ApiA、ApiB、ApiC统到一个代码包中,然后给它们加上自定义注解,注解成员设置一个包名,再把main方法中的第一行改为通过反射获取注解,得到注解之后,就得到了包名,然后通过包名反射得到该包中的所有类,就实现了最开始的目标:将所有API类放到一个代码包中,加注解的统计方法调用耗时,代码包中新增类、类下新增方法,都不必修改方法耗时统计机制。看,是不是一盘棋全活了?
> 这个示例为了简化,省略了一个比较重要的问题,那就是类的方法通常都是有参数的,这里假设的都是没有参数的方法,当然了,这个也很简单,通过反向获得参数数量和类型,然后处理相应的参数之后,将参数继续传进去就好了。
类似于这种方法耗时、日志记录、安全验证、身份验证等功能,都是和业务无关的,通过这样的封装,形成一套框架基础,那么只要框架搭起来了,开发业务的同学只需要专心写好自己的那些类似于Api*的业务类中的方法就可以了,剩下的事情都不用操心,好处多多:通用机制和业务代码逻辑完全解耦、写框架的人专心写框架、写代码的人专心写代码、通用机制可以灵活的启用停用。事实上,Java Web开发领域的事实上的标准Spring框架就是这么做的。
线程概述
学习线程,重点要掌握两方面的内容,一方面是线程的状态及切换逻辑,另一方面是线程的实现和工作过程(而这依赖于操作系统,不同的操作系统的实现是不一样的)
重点一: 线程有5种状态:
- 新建,new,创建了一个新的线程之后,它处于新建状态,注意,这里指的是未调用线程的start()方法之前
- 就绪,Runnable,又称可运行,这个是指调用了start()方法之后,特别要说明,调用了线程的start()方法,并不意味着线程就真的会立即运行起来,而是要看操作系统对线程的调度,此外,线程从睡眠和挂起状态也能转入就绪状态,即:可以再次准备运行
- 运行中,Running,这个是指线程真正获得了CPU时间片,正在执行中,此时该线程被称为当前线程,这个时候,run()方法中的代码正在被执行
- 阻塞,Blocked,这个是指线程因为某些原因放弃了CPU时间片(比如等待用户输入、等待网络返回),让出了CPU资源,暂时停止了运行。阻塞的线程如果再次被调度,会再次进入可运行状态,也有可能被解决阻塞状态,直接转入运行状态。阻塞状态3三种情况:
- 等待阻塞,这个是指调用了object.wait()方法,,此时JVM会将该线程放到等待队列中
- 同步阻塞,这个是指获取目标对象的同步锁时,该同步锁被其他线程占用着(这种情况主要是加了锁的多线程方法或代码段),此时JVM会将该线程放到锁池队列中
- 其他阻塞,这个主要是指调用了sleep()方法或join()方法,sleep()方法或join()方法如果遇到超时、中止或正常结束,线程将会再次转入可运行状态
- 死亡,Dead,线程执行结束,从run()方法中退出了(也有可能因为异常从run()方法中退出了),则该线程的生命周期结束,死亡的线程不可再生
这是一份广为流传的线程状态切换流程图:
💊 面试时经常会碰到面试官提问的问题:
- 调用线程的start方法之后,线程会立即运行对吗?答案是NO,会先判断锁,有锁进入锁池队列,无锁转入可运行状态,是否立即执行,仍然要看CPU的时间片和操作系统的线程调度。
- sleep()方法结束后线程会转入运行状态吗?答案是:NO,会转入可运行状态,是否立即执行,仍然要看CPU的时间片和操作系统的线程调度。
- 线程在运行中时没有手动调用sleep()方法和join()方法,是否有可能进入阻塞状态?答案是:YES。在类似于I/O操作中,是有可能进入阻塞状态的。
- 线程拿到锁、sleep()方法结束、join()方法结束后,会转入运行状态?答案是:NO,会转入可运行状态。所以,对于线程状态的转换,最终极的解释是:线程不能从阻塞状态、等待状态和锁状态直接转入运行状态,它只能从这些状态转入可运行状态。
重点二: Java中的线程底层是依赖于操作系统的,不同的操作系统对线程的实现不同,所以具体的调度、执行和线程管理,可能会有一些细微的差别。Java所做的,仅仅是通过Thread类,将线程映射到具体的操作系统的线程实现上去,提供了线程的一些调度方法供开发人员使用而已。所以当你打开java.lang.Thread看它的源码时,你会发现它的native方法非常多。基本上都是由底层的C和C++语言实现的。
附加几个知识点:
- 在Windows平台上,Java线程的实现使用的是C Runtime Library,即
_beginthreadexAPI族,_beginthreadex相比微软在MSDN上提供的CreatThread,增加了_tiddata块,用于解决后者存在的一些线程安全问题(比如errno以及其他一些C语言的stdio.h中的函数)
- 在Linux平台上,在2.6以上的内核,使用的是NPTL机制,线程的调度是由操作系统内核来完成的,使用的是
pthread_createAPI族,创建的用户线程与内核线程使用的是一一对应的模型
- Windows上线程的中断、唤醒、挂起和取消挂起使用的是自旋锁和Event机制实现的,即,通过指令
cmpxchg和SetEvent等API实现
- Linux平台上线程的中断、唤醒、挂起和取消挂起的操作使用的是自旋锁和线程共享全局变量以及互斥锁的方式协同实现的,即,通过指令
cmpxchg和pthread_cond_wait和pthread_mutex_lock等API实现
- Java线程的调度使用抢占式调度模型
- Java的线程优先级预定义了1到10,但是Java的线程优先级方法是native的,依赖于操作系统层面的API,但这10个优先级的定义并不与操作系统相对应,所以意义不大:
- Windows上的线程优先级是7级,由高到低分别是THREAD_PRIORITY_TIME_CRITICAL(15)、THREAD_PRIORITY_HIGHEST(2)、THREAD_PRIORITY_ABOVE_NORMAL(1)、THREAD_PRIORITY_NORMAL(0)、THREAD_PRIORITY_BELOW_NORMAL(-1)、THREAD_PRIORITY_LOWEST(-2)、THREAD_PRIORITY_IDLE(-15),此外Windows还有线程的优先级推进器(Priority Boosting)
- Linux中并没有明确地定义线程的优先级,而是提供了一套设置线程调度策略的API:
- SCHED_OTHER:分时调度策略,不支持优先级策略,也是新建线程默认值,每次调度都会通过进程的nice值(-20~19)和counter值动态决定权值,从而决定是否调度
- SCHED_FIFO:先到先服务调度策略,支持优先级策略,可定义1到99,数字越大,优先级越高
- SCHED_RR:实时调度策略,支持优先级策略,可定义1到99,数字越大优先级越,实时调度通常会得到优先调用
线程应用
在Java中创建线程,有两种方法,一是自己写一个类继承JDK自带的java.lang.Thread类,覆盖它的run方法,然后实例化这个类,再调用它的start方法,二是自己写一个类实现JDK自带的java.lang.Runnable接口,然后实例化这个类,再调用它的start方法。
通过继承java.lang.Thread类创建新线程:
package com.wasu.t.t;
public class MyThreadDemo1 extends Thread {
public static void main(String[] args) throws InterruptedException {
MyThreadDemo1 demo1 = new MyThreadDemo1();
demo1.start();
// 主线程等待一秒,防止子线程demo1还没来得及执行呢主线程就退出了
Thread.sleep(1000);
}
@Override
public void run() {
System.out.println("Thread " + Thread.currentThread().getName());
}
}
主线程等待子线程执行完毕再退出,还有一个join方法可用:
package com.wasu.t.t;
public class MyThreadDemo1 extends Thread {
public static void main(String[] args) throws InterruptedException {
MyThreadDemo1 demo1 = new MyThreadDemo1();
demo1.start();
// 主线程等待一秒,防止子线程demo1还没来得及执行呢主线程就退出了
demo1.join();
}
@Override
public void run() {
System.out.println("Thread " + Thread.currentThread().getName());
}
}
通过继承java.lang.Runnable类创建新线程:
package com.wasu.t.t;
public class MyThreadDemo2 implements Runnable {
public static void main(String[] args) throws InterruptedException {
MyThreadDemo2 demo2 = new MyThreadDemo2();
Thread thread = new Thread(demo2);
thread.start();
thread.join();
}
@Override
public void run() {
System.out.println("Thread " + Thread.currentThread().getName() + " done");
}
}
注意这种创建线程的方法,它需要一个java.lang.Thread类的实例来执行实现了java.lang.Runnable类的接口。
实现Runnable接口比继承Thread类更有优势,更灵活,因为Java中是单继承的,如果你的类已经继承了其他类了,那么它就不能再继承Thread类了,但是却可以实现多个接口,照样可以做成线程类去调用。main方法其实也是一个线程。在java中多个线程同时启动时,会同时进入就绪状态,至于什么时候,哪个先执行,完全看谁先得到CPU资源。
线程池应用
核心类
所谓线程池,就是线程的池化技术,也就是说,搞一个容器,里面放很多个线程,用的时候直接使用这里面的线程,不必每次都重新创建。之所以这么做,这是因为线程的创建和销毁的开销都是比较大的,使用现成的线程,可以避免这些问题,而且,如果每次别人调用我们的接口的时候,都创建新线程,如果请求比较密集,请求量比较大,很容易出现旧线程未执行完而新线程不断创建,要不了多久,线程创建太多,就会导致系统资源耗尽,出现OOM等程序崩溃问题。
线程池涉及到一个核心类java.uitl.concurrent.ThreadPoolExecutor,这个类提供了四个构造器:
public class ThreadPoolExecutor extends AbstractExecutorService {
// 其他代码片段省略
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler);
// 其他代码片段省略
}
其实前3个构造器最终都是调用第4个构造器的,所以我们分析它的参数含义:
- corePoolSize 核心线程池大小,注意: 在创建了线程池之后,线程池中并没有任何线程,而是有任务来了之后才会创建线程去执行任务,当然,也可以通过调用prestartAllCoreThreads()或者prestartCoreThread()方法预先创建好,但是笔者基本上没见过预先创建的。默认情况下,线程池中的线程数量为0,当有任务来了之后,创建一个线程去执行任务,当线程池中的线程数量达到corePoolSize之后,就会将后来的任务放到缓存队列中
- maximumPoolSize 最大线程数,用于控制线程池中最多能创建多少个线程
- keepAliveTime 表示线程如果没有任务时保留多长时间后终止。默认情况下,只有当线程池中的线程数量大于corePoolSize时,keepAliveTime才会起作用(换句话说,corePoolSize数量之内的线程不受keepAliveTime影响),对于数量在corePoolSize以上、maximumPoolSize以下的这些线程,空闲时间到达keepAliveTime之后就会中止。还有一个方法叫allowCoreThredTimeout(boolean)方法,调用它之后,corePoolSize数量之内的线程也会应用超时机制
- unit keepAliveTime的时间单位,可取7个值:TimeUnit.DAYS(天)、TimeUnit.HOURS(小时)、TimeUnit.MINUTES(分钟)、TimeUnit.SECONDS(秒)、TimeUnit.MILLISECONDS(毫秒)、TimeUnit.MICROSECONDS(微秒)、TimeUnit.NANOSECONDS(纳秒)。
- workQueue 阻塞队列,这个参数用来存储等待执行的任务,可以使用ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、PriorityBlockingQueue等,用的最多的是LinkedBlockingQueue。
线程相关的几个重要类和接口:
- Executor 一个顶级接口,声明了方法execute(Runnable)
- ExecutorService 接口,继承自Executor 增加了submit、invokeAll、invokeAny、shutdown、shutdownNow等方法
- AbstractExecutorService 实现了ExecutorService接口并且实现了该接口的所有方法
- ThreadPoolExecutor 继承自AbstractExecutorService
ThreadPoolExecutor类中最重要的几个方法
- execute() 向线程池提交任务
- submit() 向线程池提交任务,能够通过Future来获得线程返回结果,这个方法的底层还是调用execute()方法
- shutdown() 关闭线程池,设置线程池的状态为SHUTDOWN,调用此方法之后,线程池就不能再提交任务进去了,正在执行的任务会继续执行直到完成
- shutdownNow() 立即关闭线程池,设置线程池的状态为STOP,调用此方法之后,线程池不能再提交任务,正在提交的任务会被中断(依次调用工作线程的interrupt()方法),未执行的任务将会直接返回
应用示例
package com.wasu.t.tp;
import java.util.Random;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 线程池示例代码
*
* @author lidawei
* @date 2021/11/22 15:04
*/
public class ThreadPoolDemo1 {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
5,
10,
200, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(5));
for (int i = 0; i < 10; i++) {
executor.execute(new MyTask(i));
System.out.println("线程池中线程数目:" + executor.getPoolSize() + ",队列中等待执行的任务数目:" +
executor.getQueue().size() + ",已执行完成的任务数目:" + executor.getCompletedTaskCount());
}
executor.shutdown();
}
}
class MyTask implements Runnable {
private final int taskNum;
public MyTask(int num) {
this.taskNum = num;
}
@Override
public void run() {
System.out.println("正在执行task " + taskNum);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("task " + taskNum + " 执行完毕");
}
}
输出结果:
正在执行task 0
线程池中线程数目:1,队列中等待执行的任务数目:0,已执行完成的任务数目:0
线程池中线程数目:2,队列中等待执行的任务数目:0,已执行完成的任务数目:0
线程池中线程数目:3,队列中等待执行的任务数目:0,已执行完成的任务数目:0
正在执行task 2
线程池中线程数目:4,队列中等待执行的任务数目:0,已执行完成的任务数目:0
正在执行task 1
正在执行task 3
线程池中线程数目:5,队列中等待执行的任务数目:0,已执行完成的任务数目:0
正在执行task 4
线程池中线程数目:5,队列中等待执行的任务数目:1,已执行完成的任务数目:0
线程池中线程数目:5,队列中等待执行的任务数目:2,已执行完成的任务数目:0
线程池中线程数目:5,队列中等待执行的任务数目:3,已执行完成的任务数目:0
线程池中线程数目:5,队列中等待执行的任务数目:4,已执行完成的任务数目:0
线程池中线程数目:5,队列中等待执行的任务数目:5,已执行完成的任务数目:0
task 0 执行完毕
正在执行task 5
task 2 执行完毕
正在执行task 6
task 3 执行完毕
正在执行task 7
task 1 执行完毕
task 4 执行完毕
正在执行task 8
正在执行task 9
task 5 执行完毕
task 7 执行完毕
task 8 执行完毕
task 6 执行完毕
task 9 执行完毕
仔细分析执行结果,我们会发现:
- 刚开始往线程池中添加任务时,线程池中的线程数量也在增加,当线程池中的线程数量达到5之后,任务会进入缓存队列
- 如果你将for循环改成20次,会发现它抛出
java.util.concurrent.RejectedExecutionException异常
- 虽然线程提交的顺序是从0开始的,但是执行顺序却并不总是按这个数字往后的,这充分说明线程的执行先后顺序是不确定的,多执行几次这个程序,观察它的线程执行顺序即可得出这样的结论
!> JDK中提供了一个便捷的创建线程池的方法Executors.newCachedThreadPool();,它创建的线程池的队列大小默认是Integer.MAX_VALUE,一个不小心就会出现OOM,所以使用的时候一定要小心。
要始终牢记:线程的创建开销是非常大的,不能创建太多。根据业界前辈的经验,计算密集型的任务,创建线程的数量控制在CPU核数+1即可,I/O密集型的任务,创建线程的数量控制在2*CPU核数即可。
多线程同步
多线程同步是一个比较复杂的话题,所谓多线程同步,就是指在有多个线程的时候,通过一些手段调度这些线程,让它们按照自己的预期工作而不是胡跑乱跑。本教程从应用的角度给大家介绍几种常见的应用场景,帮助大家快速掌握和理解线程。
本章节介绍的多线程同步涉及到以下几个非常非常重要的用于控制线程同步类:
java.util.concurrent.CountDownLatch 自JDK5引入,字面意义是减数控制门闩,它通过一个计数器控制,每次调用countDown()方法,计数器减1,await()方法只会在计数器为0时都会执行,否则阻塞等待。java.util.concurrent.CyclicBarrier 自JDK5引入,字面意义是栅栏,它也拥有一个计数器,初始化CyclicBarrier的时候指明总共有几个线程,然后每个线程内部都调用await开始等待(可以设置超时,等了N久你还不来,我就走了,不等了),最后一个线程姗姗来迟,但是总算是来了,那么人到齐了,所有在栅栏处等待的线程全部被唤醒,一起出发。java.util.concurrent.CyclicBarrier的内部实现相对简单,它其实依赖于java.util.concurrent.locks.Condition。java.util.concurrent.locks.ReentrantLock 自JDK5引入,字面意思是可重入锁,它主要利用CAS+AQS实现,CAS就是比较并交换,是一些原子操作,AQS是JDK中用于构建锁和同步容器,它的核心是用一个FIFO队列控制排队等待锁的线程,每个队列节点上都维护了一个等待状态,它的核心思想是来获取锁的线程都通过CAS获取锁(有两种获取方法,公平锁和非公平锁,非公平锁是抢占式,谁抢到算谁的,公平锁是当发现有其他线程在抢锁,自己是后来的,去队尾排队),如果获取成功,就得到资源控制权,如果获取失败,就进入队列等待(此时线程会被挂起),JUC中的许多类都用到了AQS。可重入锁的意思是一个线程针对一把锁可以多次获取,每获取一次,计数器加1,释放的时候次数也要相同,每释放一次,计数器减1,最后完全释放锁。java.util.concurrent.Semaphore 自JDK5引入,字面意思是信号量,它主要用于控制访问资源的线程数量,调用acquire()会尝试申请许可,申请到了,就消耗一个许可,然后继续往下执行,没申请到,就阻塞等待,release()方法是释放许可。基于这种机制,就可以通过一个控制线程实现对其他线程的调度。
通过CAS获取锁,本质上是一种自旋锁,基于CAS实现的自旋锁本质上是利用的CPU的原子操作实现的(在C++代码层面是通过内联汇编LOCK_IF_MP指令和cmpxchg实现的,也就是通过添加lock前缀和比较交换指令实现,),适用于冲突相对较少且多核CPU的情况,如果对锁的竞争非常激烈,竞争的线程很多,使用自旋锁极有可能导致CPU开销非常大。在这里再纠正一个问题: 许多人认为CAS实现的自旋锁因为使用了cmpxchg指令,会导致总线锁,事实不然,自从Intel的80486 CPU问世(1989年)之后,基于MESI(缓存一致性协议)的设计,就已经很好了解决了这个问题,MESI在绝大多数情况下,可以很好的解决这个问题,不会导致总线锁。只有一点需要注意,即,对于任务颗粒度很小的操作,就不要单独开辟线程搞所谓的并发操作了,这个时候多线程的切换开销比线程执行的开销还要大,如果再碰到在多个CPU上针对一个变量进行频繁的竞争锁和修改,才有可能导致总线锁,而操作系统在这方面本身也有很多优化,所以基本上不必担心。
锁
锁是个比较深刻的话题,说多线程,就离不开锁。那么,什么是锁呢?锁其实就是对关键资源的控制权或者访问权、修改权。这是为了确保同一时刻只有一个线程对某个数据进行修改,所以要加锁。
不加锁的情况下,非常容易出问题,例如:用户的银行卡余额是100元,此时他在App上向他人转账80元,正在操作中,还有另外一个App发起了信用卡自动还款,要扣款50元。这个时候,明显余额是不够的,所以这两个操作最多只能成功一个,如果没有对余额加锁,保证此刻只有一个线程操作,这两个线程同时来扣余额,就会导致该用户的余额变成-30元,这明显是错误的。
通信机制
所谓通信机制,就是A线程做完某事之后,通知B线程,告诉B,自己做完了,此时B就要做自己的事情了。
通知机制有一个非常简单的做法,就是调用notify()方法或者notifyAll()方法,但是它有一个非常明显的缺点,就是“惊群效应”,A线程只想通知B线程,并不想让其他线程“惊醒”,这是浪费资源,那么有一个很简单的办法,看下面的代码:
package com.wasu.t.mt;
/**
* 线程A打印0 1 2 3 4之后,线程B再打印0 1
*
* @author lidawei
* @date 2021/11/22 16:00
*/
public class NotifyModeDemo {
private static final Object object = new Object();
public static void main(String[] args) {
new Thread(() -> {
for (int i = 0; i < 5; i++) {
try {
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName() + "->" + i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
synchronized (object) {
object.notify();
}
}, "ThreadA").start();
new Thread(() -> {
synchronized (object) {
try {
object.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
for (int i = 0; i < 2; i++) {
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName() + "->" + i);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "ThreadB").start();
}
}
输出:
ThreadA->0
ThreadA->1
ThreadA->2
ThreadA->3
ThreadA->4
ThreadB->0
ThreadB->1
用这种方式,可以保证ThreadA的任务先于ThreadB执行,即使把ThreadB的代码放到ThreadA前面也没问题,同学们可以自己测一下。
事实上,要实现这种逻辑,还有一种方法,是通过Codition,只不过使用起来略显复杂,不属于初级掌握内容,暂时不涉及,以后笔者再来补充吧。
synchronized 原理剖析
通过关键字synchronized来锁住某个关键资源,是Java中最常见的一种锁机制。synchronized关键字的实现原理是,以synchronized关键字约束的代码块,进入进会有一个monitorenter指令,退出时会有一个monitorexit指令,在Java中的每个对象上,都有一个标记位,用于标记该对象是否被线程锁了,这个标记位叫监视器锁(monitor),synchronized锁引用的对象当然也有这个监视器锁monitor,监视器锁monitor为0时,线程可以访问该对象,然后将监视器锁monitor设为1,此时其他线程再来,发现该对象的监视器锁monitor已经被占用了,就进入阻塞状态,当后来的其他线程发现监视器锁monitor为0时,会重新尝试获取该对象的锁。同一个线程通过synchronized反复进入锁定对象的监视器锁monitor,则监视器锁会往上累加1,每退出synchronized的锁引用对象一次,就释放一次锁,就减1,直到为0,则释放该对象的锁,此时其他线程会有可能获得该对象的锁。前面所述是通过synchronized关键字引用变量实现锁的机制,这个变更可以是自己定义的一个变量(如前代码所示的Object,此时锁定该对象),也可以是某个this变量(此时锁定该实例),还可以是类的class对象(类名.class)此时锁定整个类。那么,当synchronized标记在方法上的时候,又是怎样的呢?其实这个时候,JVM的常量池中会有一个ACC_SYNCHRONIZED标记,用于控制该方法的线程锁,某个线程想要调用该方法,就会检查该方法的ACC_SYNCHRONIZED访问标记是否设置了,如果设置了,就去尝试获取锁。
> 注意,如果被synchronized标记的方法不是静态方法,那么它是方法所在类的实例级的,所以,当线程发现该方法的ACC_SYNCHRONIZED标记设置了的情况下,就会去竞争该类的实例的监视器锁monitor,如果被synchronized标记的方法是静态方法,那么它不是方法所在类的实例级的,它是类级的,所以当线程发现该方法的ACC_SYNCHRONIZED标记设置了的情况下,会去竞争该类的监视器锁monitor(即:类名.class的监视器锁)。
代码:
public class Sync {
private int a = 0;
public void add(){
synchronized(this){
System.out.println("a values " + ++a);
}
}
}
使用javap -c Sync反编译上述代码的.class文件,得到它的字节码文件,我们会看到如下信息:

由反编译结果可以看出:synchronized代码块主要是靠monitorenter和monitorexit这两个原语来实现同步的。当线程进入monitorenter获得执行代码的权利时,其他线程就不能执行里面的代码,直到锁Owner线程执行monitorexit释放锁后,其他线程才可以竞争获取锁。
Java虚拟机规范中对synchronized相应的这两个线程同步锁的原语有下面的约束:
- monitorenter 每一个对象都有一个监视器锁monitor,当monitor被占用时,就处于锁定状态,其他线程不能进入。线程执行monitorenter时会尝试获取监视器锁monitor的所有权
- monitorexit 执行monitorexit的线程必须是锁引用对象的监视器锁monitor的持有者线程
同步机制
同步机制,分为两种:同时去做某件事情、分别完成多项任务。
同时做某件事情
遇到多项任务的时候,我们开多个线程,让它们步调协调一致,分别去做某件事情。这样可以大幅提升效率,事件事件任务的耗时是最慢的那个任务耗时,而不是所有任务耗时的合计。
要实现这样的功能,做法有很多种,我们取最常见的一种方法,使用CyclicBarrier这个工具类,有的人称其为栅栏,取意所有人都在等待,时间到了一起冲过栅栏,也就是发令枪的模式,代码如下:
package com.wasu.t.mt;
import java.time.LocalDateTime;
import java.util.Random;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
/**
* 多线程同时开跑(发令枪模式)
*
* @author lidawei
* @date 2021/11/22 16:58
*/
public class ReadyGoModeDemo {
public static void main(String[] args) throws InterruptedException {
final int threadNum = 5;
CyclicBarrier barrier = new CyclicBarrier(threadNum);
for (int i = 0; i < threadNum; i++) {
new Thread(() -> {
try {
Thread.sleep(new Random().nextInt(1000) + 2000);
System.out.println(LocalDateTime.now() + ":::" + Thread.currentThread().getName() + "就绪");
barrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println(LocalDateTime.now() + ":::" + Thread.currentThread().getName() + " 完成了任务");
}, "Thread-" + i).start();
}
Thread.sleep(3000);
}
}
执行结果:
2021-11-22T17:13:28.932:::Thread-2就绪
2021-11-22T17:13:28.993:::Thread-3就绪
2021-11-22T17:13:29.243:::Thread-0就绪
2021-11-22T17:13:29.330:::Thread-1就绪
2021-11-22T17:13:29.669:::Thread-4就绪
2021-11-22T17:13:29.669:::Thread-4 完成了任务
2021-11-22T17:13:29.669:::Thread-2 完成了任务
2021-11-22T17:13:29.669:::Thread-3 完成了任务
2021-11-22T17:13:29.669:::Thread-1 完成了任务
2021-11-22T17:13:29.669:::Thread-0 完成了任务
多执行几次,你会发现这五个线程始终会等待最后一个线程到了之后,大家再一起出发去“完成任务”。
等待多个线程都完成
在许多时候,我们将任务分派给多个线程之后,要等待它们都完成,然后再继续做我们的事情。
这个实现方法也有很多种,我们先来一个最常见也最容易的,使用CountDownLatch的方式,代码如下:
package com.wasu.t.mt;
import java.time.LocalDateTime;
import java.util.Random;
import java.util.concurrent.CountDownLatch;
/**
* 多个线程都完成了,任务才结束
*
* @author lidawei
* @date 2021/11/22 17:17
*/
public class MultiThreadAllDoneDemo {
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(5);
for (int i = 0; i < 5; i++) {
new Thread(() -> {
try {
Thread.sleep(new Random().nextInt(1000) + 2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(LocalDateTime.now() + ":::" + Thread.currentThread().getName() + "任务完成了");
latch.countDown();
}, "Thread-" + i).start();
}
latch.await();
System.out.println(LocalDateTime.now() + ":::" + Thread.currentThread().getName() + "所有任务都完成了");
}
}
运行结果如下:
2021-11-22T17:20:09.200:::Thread-4任务完成了
2021-11-22T17:20:09.217:::Thread-0任务完成了
2021-11-22T17:20:09.366:::Thread-1任务完成了
2021-11-22T17:20:09.402:::Thread-2任务完成了
2021-11-22T17:20:09.541:::Thread-3任务完成了
2021-11-22T17:20:09.541:::main所有任务都完成了
生产者消费者模型
消费者生产者模型是实践中应用非常广泛的一种技术,它能够将两部分的业务逻辑完全剥离开来,大幅降低系统设计的复杂性,提升代码的聚合性,避免多个业务模块的强耦合,对于优化代码,降低开发成本、提升开发效率都有重要意义。生产者消费者模型有很多种实现方法,我们在队列的章节已经用阻塞队列实现了一个生产者消费者模型,在这里,我们再讲两种实现方法。
实现一:基于可重入锁实现
package com.wasu.t.c_and_p;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
/**
* 使用可重入锁实现生产者消费者模型
*
* @author lidawei
* @date 2021/11/23 9:42
*/
public class ProducerAndConsumerDemo {
public static void main(String[] args) {
final ReentrantLock lock = new ReentrantLock();
Condition conditionProducer = lock.newCondition();
Condition conditionConsumer = lock.newCondition();
final int max = 10;
new Thread(new Producer(lock, conditionProducer, conditionConsumer, max), "ProducerThread").start();
new Thread(new Consumer(lock, conditionProducer, conditionConsumer, max), "ConsumerThread").start();
}
}
class Producer implements Runnable {
final ReentrantLock lock;
final Condition conditionProducer;
final Condition conditionConsumer;
final int max;
public Producer(ReentrantLock lock, Condition conditionProducer, Condition conditionConsumer, int max) {
this.lock = lock;
this.conditionProducer = conditionProducer;
this.conditionConsumer = conditionConsumer;
this.max = max;
}
@Override
public void run() {
int i = 1;
while (true) {
//获取锁
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + ":::" + i);
if (i >= max) {
conditionConsumer.signal();
break;
}
conditionConsumer.signal();
conditionProducer.await();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
i++;
}
}
}
}
class Consumer implements Runnable {
final ReentrantLock lock;
final Condition conditionProducer;
final Condition conditionConsumer;
final int max;
public Consumer(ReentrantLock lock, Condition conditionProducer, Condition conditionConsumer, int max) {
this.lock = lock;
this.conditionProducer = conditionProducer;
this.conditionConsumer = conditionConsumer;
this.max = max;
}
@Override
public void run() {
int i = 1;
while (true) {
//获取锁
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + ":::" + i);
if (i >= max) {
conditionProducer.signal();
break;
}
conditionProducer.signal();
conditionConsumer.await();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
i++;
}
}
}
}
执行代码输出:
ProducerThread:::1
ConsumerThread:::1
ProducerThread:::2
ConsumerThread:::2
ProducerThread:::3
ConsumerThread:::3
ProducerThread:::4
ConsumerThread:::4
ProducerThread:::5
ConsumerThread:::5
ProducerThread:::6
ConsumerThread:::6
ProducerThread:::7
ConsumerThread:::7
ProducerThread:::8
ConsumerThread:::8
ProducerThread:::9
ConsumerThread:::9
ProducerThread:::10
ConsumerThread:::10
这份示例代码,充分体现了消费者通知生产者、生产者通知消费者的逻辑关系:当生产者前进一步后,通知消费者,当消费者前进一步后,再通知生产者,如此就做到了“步调协调一致”了。
这份示例代码,也是一道非常常见的面试题:两个线程交替打印数字。
实现二:基于信号量实现
请看代码:
package com.wasu.t.c_and_p;
import java.util.Random;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* 通过信号量Semaphore实现生产者和消费者协同工作
*
* @author lidawei
* @date 2021/11/23 14:02
*/
public class SemaphoreDemo {
public static void main(String[] args) throws InterruptedException {
ExecutorService service = Executors.newCachedThreadPool();
// 创建Semaphore信号量,初始化指定数量的许可
final Semaphore sp = new Semaphore(1);
// 这些任务都是消费者
for (int i = 0; i < 5; i++) {
service.submit(() -> {
try {
// 先尝试获取许可,一旦获得成功,sp中的许可数量会减少
sp.acquire();
System.out.println("线程" + Thread.currentThread().getName() + "进入:::" + sp.availablePermits());
// 模拟线程工作中...
Thread.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程" + Thread.currentThread().getName() + "离开:::" + sp.availablePermits());
});
}
// 创建一个控制线程作为生产者
Thread thread = new Thread(() -> {
for (int i = 0; i < 5; i++) {
try {
Thread.sleep(new Random().nextInt(1000) + 1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
sp.release();
System.out.println("控制线程释放一个许可:::" + sp.availablePermits());
}
}
System.out.println("控制线程结束");
});
thread.start();
service.shutdown();
while (!service.isTerminated()) {
Thread.sleep(1000);
}
}
}
运行代码结果:
线程pool-1-thread-1进入:::0
线程pool-1-thread-1离开:::0
控制线程释放一个许可:::1
线程pool-1-thread-2进入:::0
线程pool-1-thread-2离开:::0
控制线程释放一个许可:::1
线程pool-1-thread-3进入:::0
线程pool-1-thread-3离开:::0
控制线程释放一个许可:::1
线程pool-1-thread-4进入:::0
线程pool-1-thread-4离开:::0
控制线程释放一个许可:::1
线程pool-1-thread-5进入:::0
线程pool-1-thread-5离开:::0
控制线程释放一个许可:::1
控制线程结束
研究上述代码,我们可以得知,控制线程每释放一个许可,消费者就进来消费,直到所有许可都消耗完(上述代码中是5个),你可以尝试修改初始化Semaphore的时候的许可数量,也可以尝试修改生产者和消费者的模拟执行的sleep的时间,你会发现它们的行为都会有所不同,通俗的解释就是:信号量Semaphore用于约束有几个口子可以让消费者进来消费,而模拟的sleep时间,其实就是看在实践中到底是生产者的动作快还是消费者的动作快,做东西的人动作快,买东西的人就不必等,可以一拥而上,做东西的人动作慢,买东西的人就得等,就得排队。
多线程使用攻略
线程的使用是非常频繁而又非常容易出问题的,使用的好,代码性能很高、解耦很好,很优雅,维护起来也很容易,使用的不好,线程失控,那么就会各种莫名其妙的问题层出不穷,令人防不胜防。
字节码与JVM指令
通过前面章节的学习,我们已经掌握了基本的Java编程方法。现在,我们再继续深入介绍一番。
先说JDK
JVM,是Java虚拟机的简称,但是你也可以理解它是一套规范,Java官方针对虚拟机这种技术提供了一整套规范(设计这套规范的目的,就是为了实现跨平台,屏蔽底层的硬件和操作系统的差异,让大家做到Write Once, Run Anywhere),在这套规范之下,有很多种JVM实现,当然了,官方在出台这一套规范的同时,也搞了一套JVM实现,就是美国的Oracle公司出品的Oracle JDK,除此之外,还有社区开源版本OpenJDK,还有Github上第三方大神想要把Java搞的让它支持动态语言而弄出来的GraalvmJDK,以及蓝色巨人IBM、国际上云计算的巨头Amazon、开源巨头Redhat等国际大厂商也有自己的JDK,IBM的好像叫IBM Runtimes for Business,反正我也没用过,国内阿里巴巴也在搞自己的JDK。最常用的是官方的OracleJDK(因为根正苗红)和社区的OpenJDK(因为许多Linux发行版自带)。
所以,要注意:JDK ≠ Oracle JDK ,它们不是一回事。
两个重要的问题:
- Oracle发布的JDK8,是目前应用最广泛的版本,这个版本有一个特点,那就是Oracle官方对它的支持已经结束了,再没有免费的版本更新了,要再获得更新,或者想要Oracle给你提供JDK8相关的支持,需要付费。Oracle发布的JDK11,如果没有交钱,不允许商用,想要使用JDK11,只能使用OpenJDK。
- 关于JDK是GPL协议的问题,GPL协议的内容,简单介绍就一句话,某软件使用了GPL协议的软件组件或库,那么这个软件就要开源,不能商用。这个要澄清一点,它这个GPL协议,指的是你把人家的JDK拿来修改了一下,然后发布了自己的JDK,那么你得开源,不能免费,而不是说Java语言,这不是一回事。
再说字节码和指令集
字节码我们前面也已经介绍过了,同学们也都大体上知道了,在这里再说一下,字节码是平台无关的,要运行字节码,需要JRE,而Java虚拟机JVM,它本身并没有做任何编程语言的编写,从理论上讲,基于JVM这一套规范,我们可以写一个JDK,让它运行任何语言,事实上业界已经有人在这么干,基于JVM规范搞的JDK,除了能运行Java语言之外,还能运行Groovy语言、Scala语言、Python语言、Ruby语言等等,如下图所示:

JVM规范中对字节码和指令集都有说明,英语好又有兴趣的同学可去看看: https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-6.html#jvms-6.5
Java虚拟机的指令由一个字节长度的、代表着某种特定操作含义的数字(称为操作码,Opcode)以及跟随其后的零至多个代表此操作所需参数(称为操作数,Operands)而构成。
我们来看一个示例代码:
public class Hello {
public static void main(String[] args) {
int a = 1;
}
}
将上述Java代码编译成字节码之后,再使用javap -c Hello.class指令将字节码文件反编译一下,得到以下内容:
Compiled from "Hello.java"
public class Hello {
public Hello();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: iconst_1
1: istore_1
2: return
}
这里可以看到最主要的指令:
- aload_0 this指针压栈
- invokespecial 调用实例的初始化方法
- iconst_1 将一个常量加载到操作数栈
- istore_1 将一个数值从操作数栈存储到局部变量表
字节码是一个比较高深的话题,同学们先了解这些就足够了,以后有其他需要再研究学习吧。
Java内存模型
Java内存模型又称为JMM(Java Memory Mode),Java在JDK6及以前、JDK7、JDK8这三个目前最主要的流行版本上,内存模型还是有些变化的,如下图所示:

图上对各代JDK的内存模型都展示的很形象,还有7点重要信息也简单易懂,相信同学们看到这里就基本上明了了。下面我们说说Java内存模型在程序运行中的一些知识点。
!> 注意,网上有很多文章说到JDK8之后,永久代不存在了,所以,常量池就不在堆中了,而是在方法区(也就是元空间)中。这个说法是错误的,在JDK6中才是这样的,JDK7和8都不是这样的。按照JVM规范,运行时常量池是方法区的一部分,用于存放编译期生成的各种字面量(字面量你可以理解为在源代码中被明文书写的数字、文本字符串等)和符号引用(符号引用的概念来自编译原理,是指类和接口的全限定名、字段名称和描述符、方法名称和描述符等),但是目前按照JDK8的实现,它的常量池分为三类:一是类文件中的静态常量池(主要是符号引用),存在于.class文件中、二是运行时常量池(主要是class文件元信息、编译后的代码数据、引用类型数据),存在于元空间中、三是字符串常量池,存在于堆中(自JDK7之后)。所以,自JDK7之后,已经不会出现PermGen Space这样的OOM错误了,JDK8中的命令行选项PermSize和MaxPermGen也已经无效了(如果你加上,程序启动的时候会给出警告)。所以,自JDK7之后,字符串常量池在堆中,并且它是一个Hash表,里面存放的是字符串常量(也就是我们在代码中用双引号写的那些字符串常量)。然后,在堆中会有变量引用指向这些字符串常量,实现字符串的使用。
符号引用是编译原理中非常重要的一个概念,对于Java来说,一个Java程序启动的时候,会加载很多类,有JDK的,也有我们自己定义的,那么,对于这样的代码String str = new String("hello");,怎么在虚拟机中找到String这个类呢?有人说这还不简单吗?大家都知道String类是java.lang.String啊,是的,但仅仅知道这些是不够的,JVM刚刚启动的时候,类还没有加载进来,它不知道有哪里类,它要做的一件事情就是将各用要用到的.class文件都加载到常量池中,这些类的全限定名称、字段的名称、方法名称以及作用于它们的修饰符都是固定的,不会变,所以也是常量,JVM会判断java.lang.String是否被用到了,用到了就加载String类的.class文件到方法区,之后我们就可以在运行时常量池中将原来的符号引用替换为直接引用了。
前面讲类加载机制的时候,我们已经说过,类的加载过程吩为加载、连接(含验证、准备、解析)、初始化、使用、卸载这几个阶段,而将.class文件中的静态常量池中的符号引用加载到方法区中的运行时常量池中的这个操作,发生在加载阶段,而将符合引用替换为直接引用的操作,发生在解析阶段。
根据JDK8的JVM规范,JDK的字节码中,对静态常量池和运行时常量池的常量表有定义如下:
CONSTANT_Utf8 1 // UTF-8编码的Unicode字符串
CONSTANT_Integer 3 // int类型的字面值
CONSTANT_Float 4 // float类型的字面值
CONSTANT_Long 5 // long类型的字面值
CONSTANT_Double 6 // double类型的字面值
CONSTANT_Class 7 // 对一个类或接口的符号引用
CONSTANT_String 8 // String类型字面值的符号引用
CONSTANT_Fieldref 9 // 对一个字段的符号引用
CONSTANT_Methodref 10 // 对一个类中方法的符号引用
CONSTANT_InterfaceMethodref 11 // 对一个接口中方法的符号引用
CONSTANT_NameAndType 12 // 对一个字段或方法的部分符号引用
我们看这段代码:
public class Demo {
public static void main(String[] args) {
int i = 1;
}
}
那么按照前述理论,上述代码编译之后,数字1作为字面量,就应该在常量池中找到CONSTANT_Integer为1的项,但是当你深入研究之后,你会发现它并不存在,如果你把代码改成int i = 32768,我们才能在常量池表中找到CONSTANT_Integer为132768的项,这是因为对于整数字面量来说,如果值在-32768~32767 范围内,都会被直接嵌入指令中,而不会保存在常量区,对于 long、double 都有一些类似的情况,比如long l = 1L、double d = 1.0,但是如果你把代码改成final int i = 1,却是可以在常量池中找到CONSTANT_Integer为132768的项。
内存管理方法论
先说堆和栈
堆和栈其实仅仅是程序在运行时在内存中划分了一块区域,这些区域有自己独特的管理和使用方法,所以就分别起了个名字。
堆是一块通常分配的较大的空间,里面可以存放的内容自然就很多了,它是各个线程可以共享的,所以有可能出现多个线程抢占的资源冲突问题。
栈的空间相对来说就要小的多,一般就是几百KB、1MB、2MB这个量级,不会更大的,栈是各个线程自己管理和维护的,对于其他线程来说是独立封闭的一块空间,而且栈中的数据存取遵循后进先出(FILO)原则,数据入栈,称为压栈,数据出栈,称为弹出栈。栈主要保存方法中的局部变量、方法参数、返回值、对堆中的对象的引用信息等。
> Java中的栈分为两种,一种是Java方法栈,一种是本地方法栈,Java方法栈是指运行用Java语言实现的Java代码的时候所使用的栈,本地方法栈和Java方法栈不同,它的声明类似于public static native Thread currentThread();,这个方法我们可以调用,但是我们看不到它的实现,它的实现是用C++写的(Java语言底层本身也是用C和C++开发出来的),虽然如此,但是这些方法在调用的过程中,仍然会有栈用来维护方法参数、返回值、方法内的局部变量等信息,所以这些用native标识了的本地方法,仍然有本地方法栈。
网上有大神做了一张图,借来用一下:

看上图我们就可以快速知道JVM的内存结构了。请同学们仔细看,多看看,要记住这张图的结构,我再用文字表述一遍:
- JVM内存仍然由堆、栈、方法区构成
- 堆主要有新生代和老年代
- 方法区是JVM规范中的一个概念,在JDK6及以前,称为永久代,JDK8称为元空间(Metaspace)
- 栈分为Java虚拟机站(也就是Java方法栈)和本地方法栈(也就是native方法栈)
- 新生代按8:1:1的比例划分为三部分:Eden(又称为伊甸园区)、Survivor from区、Survivor to区
Java中栈的大小
这是一个非常值得探究的问题,那么答案是什么呢?要弄清楚这个问题,我们得去分析研究OpenJDK8的源代码,以及它的JVM的源码。
先看Linux平台上JVM的源码src/os_cpu/linux_x86/vm/globals_linux_x86.hpp:
#ifdef AMD64
define_pd_global(intx, ThreadStackSize, 1024); // 0 => use system default
define_pd_global(intx, VMThreadStackSize, 1024);
#else
// ThreadStackSize 320 allows a couple of test cases to run while
// keeping the number of threads that can be created high. System
// default ThreadStackSize appears to be 512 which is too big.
define_pd_global(intx, ThreadStackSize, 320);
define_pd_global(intx, VMThreadStackSize, 512);
#endif // AMD64
由上述代码我们可以知道,默认情况下,64位的Linux平台上的OpenJDK8的默认情况下,Java虚拟机栈的大小是1MB,Java native栈的大小也是1MB。32位的Linux平台上Java栈的大小是320KB,Java native栈的大小是512KB。
再看Windows平台上JVM的源码src/os_cpu/windows_x86/vm/globals_windows_x86.hpp:
// Default stack size on Windows is determined by the executable (java.exe
// has a default value of 320K/1MB [32bit/64bit]). Depending on Windows version, changing
// ThreadStackSize to non-zero may have significant impact on memory usage.
// See comments in os_windows.cpp.
define_pd_global(intx, ThreadStackSize, 0); // 0 => use system default
define_pd_global(intx, VMThreadStackSize, 0); // 0 => use system default
由上述代码我们可以知道,在Windows平台上,Java线程栈的大小默认是从java.exe中获得的,并且java.exe有一个默认值,32位平台默认是320K,64位平台默认是1MB,但不是绝对的,它和Windows的版本有关。人家还特别说明了,修改栈大小对内存的使用有重大影响,具体的信息要看os_windows.cpp的注释。我们找到文件,相关注释在该文件的570行,我已经看过了,再给大家简单地翻译一下:Windows上的线程不是使用Win32 SDK中的CreateThread这些API族创建的,而是使用C Runtime Library中的_beginthreadex这些API族创建的,所以它的栈大小和线程创建时的指定方式、PE头文件中的编译进去的信息以及Windows系统版本有关,而且XP系统之后,又多出来了一个STACK_SIZE_PARAM_IS_A_RESERVATION标识符,总之,Windows系统上的栈大小的问题确实是有点复杂。
不显式的设置-Xss或-XX:ThreadStackSize,或者把-Xss或者-XX:ThreadStackSize设为0,就是使用“系统默认值”。
线程的工作空间和线程安全问题
每个线程创建的时候,就会有自己的一块专属的内存空间,称为工作内存,虽然这个工作内存也是物理内存,但是在逻辑上它们是分开管理的,不是一回事。而且每个线程的工作内存是私有的,别人不能访问。线程访问堆内存时,不能直接访问,如下图所示:

!> 看图我们就能知道,如果多个线程同时修改某个共享变量(堆中的这些共享资源),就极有可能导致线程安全问题,简单地,A线程从主内存读取了一个变量a,得到值1,此时如果A线程简单地认为自己使用的变量a及其副本都再没人使用,是安全的,给a加1,然后回写主内存,那么,按照预期,主内存的新值是2,但是,对于一个软件系统来说,多人同时在用是很正常的,那就不可能让来使用系统的人去排队顺序访问系统,只能使用多线程并发访问,此时B线程和A线程执行同样的代码,都从主内存中取得了变量a,A线程服务于用户U1,用户U1的诉求是对这个数据加1,得到2,B线程服务于用户U2,用户U2的诉求是对这个数据加2,得到3,两个线程都在自己的工作内存中完成了数据运算,和主内存同步的时候,就出问题了,主内存中的a,到底是以线程A的U1为准呢?还是以线程B的U2为准呢?如果不解决这个问题,那么各线程所服务的各用户的最终结果数据是不可预测的。这就是著名的线程安全问题。
详解JDK8的JVM内存模型
在这里我们借用网上大神的图片来说明:

由图我们可以清楚地看到,JVM内存模型分为5部分:
- 方法区 再强调一遍,这是JVM规范的名称,实际上叫元空间
- Java虚拟机栈 Java方法使用
- 本地方法栈 native方法使用
- 堆 存入各类对象,具体存什么,前文已经有很多介绍了
- 程序计数器 记录JVM指令的执行位置,当有方法来回跳转时,必须要记住执行到什么位置了
关于栈,可以再说一说,在Java中,每当开启一个线程(包括进入main方法开启的main线程),就会有一个栈,每进入一个方法,就会在栈上创建一个栈帧,栈帧中就包含要完成该方法执行的所有相关内容,包括局部变量表、操作数栈、动态链接、返回地址等相关信息,调用一个方法的时候,创建一个栈帧,此栈帧相关信息入栈,方法调用完毕了,该方法相关的栈帧数据出栈,内存被回收。所以,main方法的栈帧,当然是在main线程的栈的最底部。
再说Java中的字符串类型
我们看一段代码:
String s1 = new String("he") + new String("llo");
String s2 = s1.intern();
System.out.println(s1 == s2);
问:这段代码输出什么?创建了几个String对象?
答:在JDK6中,输出false,创建了6个对象,在JDK7中,输出true,创建了5个对象。
原理详解:
在JDK6中,第一行代码执行时,he、llo两个字符串字面量在永久代中,堆区又创建了两个字符串对象he和llo,紧接着两个字符串拼接,在堆中生成了新的字符串hello,第二行代码执行时,将刚在堆中新生成的字符串hello放入常量池,于是常量池中也有一个hello字符串,所以,总共是6个String对象,此时s1指向堆中的hello,s2指向常量池中的s2,所以它们不相同,于是输出false。
在JDK7中,第一行代码执行时,he、llo两个字符串字面量在堆中,堆区又创建了两个字符串对象he和llo,紧接着两个字符串拼接,在堆中生成新的字符串hello,第二行代码执行时,目的是将新生成的字符串hello放入常量池,但该字符串常量池本身就在堆中,所以不必再做任何事,只需返回该字符串的引用即可,所以总共是5个String对象,此时s1指向堆中的hello,s2也指向堆中的hello,它们指向了同一个字符串,所以输出true。
垃圾回收GC
GC是Garbage Collection的缩写,即:垃圾回收。因为学习GC时涉及到Java的内存模型的相关知识,所以请同学们学完Java内存模型章节的内容之后再来学习GC,这样会更容易理解和掌握这些内容。
什么是GC
垃圾收集是许多编程语言的特性,有C、C++语言开发经验的同学都知道,它们的内存是由程序员自己管理的,当我要存储一些数据的时候,我要先向操作系统申请一块内存,然后把数据存进去,数据用完了,我要明确地用代码表示这些内存不需要了,进行回收操作(C语言中常用的是malloc函数和free函数,C++是用new操作符申请内存,用delete操作符释放内存)。而Java语言,内存是由JVM自己管理的,一般情况下,程序员不必关心内存的使用问题,所以,这样的编程语言,就有一套垃圾回收机制,变量不使用了,它所占用的内存,就收JVM进行回收,Python语言、Go语言,也都有自己的GC机制。Java程序可以通过命令行参数对GC的众多参数进行配置,下面我们在学习的过程中会逐步介绍到。
Java语言的内存管理:
public class GcDemo {
public static void main(String[] args) {
m();
}
public static void m() {
String s = new String("Hello");
System.out.println(s);
}
}
对于这段代码来说,方法m()中的s变量在堆上申请了一块内存,用于保存字符串hello,这个方法返回之后,我们就不必管它了,刚才占用的内存会自动回收。我们再来看一段C代码:
#include <stdio.h>
#define MAX_BUF_SIZE 100
void m()
{
char *p = (char *)malloc(MAX_BUF_SIZE);
if (p != NULL)
{
memset(p, 0, MAX_BUF_SIZE);
strcpy(p, "Hello");
printf("%s\n", p);
free(p);
}
}
int main(int argc, char *argv[])
{
m();
}
对于这段代码来说,函数m()中申请的了一块内存,指针p指向它,使用完了之后,必须要通过手动方式free(p)进行回收,否则就会造成内存泄露。
- 手动管理内存模式,手动管理内存相对来说是比较麻烦的,程序员不仅仅要考虑业务逻辑的实现,还要很精细地管理好内存。谷歌首席软件工程师罗布·派克(Rob Pike)曾经在谈到Go语言的发布的时候说:我们之所以开发Go,是因为过去10多年间软件开发的难度令人沮丧。所以,对于大型、超大型的软件系统,让程序员自己去管理内存,事实上是一件非常困难的事情,也是一件非常繁杂的事情。但是手动管理内存也并非一无事处,管理的好,程序的效率会非常高,资源开销也会很小,所以,在一些资源占用非常敏感、性能非常敏感的软件开发领域,C和C++一直是事实上的王者。
- 自动管理内存模式,自动管理内存模式相对于程序员来说,解放了手动管理内存的精力和时间,可以让他们在业务逻辑系统方面投入更多,从而更好的产出,做出更优秀的系统和产品,但是劣势也是很明显的,内存的自动管理历经多年发展演变,仍然没有达到让人理想的程度,经常会出现内存占用逐渐上升却无法做到回收的问题,对于一些生命周期较长的对象的回收,也存在很多困难,自动管理内存的世界级难题SWT(Stop The World,回收内存时程序要完全停止运行,回收完了再恢复运行)至今也只是优化到了可以接受的程度,并没有做的非常好。
GC机制
在JVM中,程序计数器、虚拟机栈、本地方法栈都是随线程而生随线程而灭,栈帧随着方法的进入和退出会有相应的入栈和出栈操作,已经实现了自动的内存清理,因此,我们的内存垃圾回收主要集中于Java的堆和方法区中,在程序运行期间,这部分内存的分配和使用都是动态的。
什么时候会做内存回收的动作呢?两种情况:
- 程序调用
System.gc()时可以尝试触发,之所以说尝试触发,是因为我们在代码中手动调用了这个方法,只是通知JVM的GC线程去做垃圾回收的工作,GC线程到底会不会做,不一定,这仍然依赖于JVM的具体实现和线程调度。
- 系统自身来决定GC触发的时机,这是最核心的,尤其是内存大小不足时,会启动GC线程并停止应用线程的执行,然后开始回收。
老年代、新生代、方法区的垃圾回收的具体做法是不相同的,这个后面我们还会深入学习。
GC对象
需要进行回收的对象就是已经没有存活的对象,判断一个对象是否存活常用的有两种办法:引用计数和可达分析。
- 引用计数:每个对象有一个引用计数属性,新增一个引用时计数加1,引用释放时计数减1,计数为0时可以回收。此方法简单,但是无法解决对象相互循环引用的问题。
- 可达性分析(Reachability Analysis):对对象的管理,使用一棵树管理起来,根节点叫GC Roots,从GC Roots开始向下搜索,搜索所走过的路径称为引用链。当一个对象到GC Roots没有任何引用链相连时,则证明此对象已经没有任何人指向它了,它现在是不可用的,是不可达对象,那么可以回收。
GC算法
GC常用的算法有:标记-清除算法,标记-压缩算法,复制算法,分代收集算法。目前主流的JVM(Oracle的Hotspot)采用的是分代收集算法。
- 标记-清除算法,为每个对象存储一个标记位,记录对象的状态(活着或是死亡),分为两个阶段,一个是标记阶段,这个阶段内,为每个对象更新标记位,检查对象是否死亡;第二个阶段是清除阶段,该阶段对死亡的对象进行清除,执行 GC 操作。
- 标记-压缩算法,是标记-清除法的一个改进版,不同的是,在第二个阶段,该算法并没有直接对死亡的对象进行清理,而是将所有存活的对象整理一下,放到另一处空间,然后把剩下的所有对象全部清除。这样可以避免标记-清除算法反复清除的过程中造成大量的内存空间碎片。
- 复制算法,该算法将内存平均分成两部分,然后每次只使用其中的一部分,当这部分内存满的时候,将内存中所有存活的对象复制到另一个内存中,然后将之前的内存清空,只使用这部分内存,循环下去。这个算法与标记-整理算法的区别在于,该算法不是在同一个区域复制,而是将所有存活的对象复制到另一个区域内。很明显,需要一倍以上的内存空间,并且内存空间比较大时,让程序完全停止运行,然后复制一遍,开销是非常大的。
- 分代收集算法,现在的虚拟机垃圾收集大多采用这种方式,它根据对象的生存周期,将堆分为新生代(Young)和老年代(Tenure)。在新生代中,由于对象生存期短,每次回收都会有大量对象死去,那么这时就采用复制算法。老年代里的对象存活率较高,没有额外的空间进行分配担保,所以可以使用标记-整理 或者 标记-清除。其中新生代(Young)又分为Eden区,From区与To区。
分代收集算法的具体做法是这样的,当系统创建一个对象的时候,总是在Eden区操作,当这个区满了,那么就会触发一次YoungGC,也就是年轻代的垃圾回收。一般来说这时候不是所有的对象都没用了,所以就会把还能用的对象复制到From区。这样整个Eden区就被清理干净了,可以继续创建新的对象,当Eden区再次被用完,就再触发一次YoungGC,然后要注意,这个时候跟刚才稍稍有点区别。这次触发Young GC后,会将Eden区与From区还在被使用的对象复制到To区,再下一次YoungGC的时候,则是将Eden区与To区中的还在被使用的对象复制到From区。一些对象在经过若干次Young GC后,还在From与To之间来回游荡(每次游荡,年龄增加1岁),这时候From区与To区亮出了底线(阈值,超过了15岁),这些家伙要是到现在还没活着呢,回收不了,那就统统移动(复制)到老年代。 重复前述过程挺长时间的情况下,老年代空间也越来越满,那就触发Full GC(集体大扫除),进行一次全面清理和回收。收此可见,全面的清理和回收(也就是Full GC)对系统的性能影响也是很大的,应当尽量避免这种情况频繁出现。
垃圾收集器
启动一个Java程序时,可以在命令行上通过参数指定垃圾收集器,下面逐个介绍这些常见的垃圾收集器。
- Serial收集器,又称串行收集器,通过命令行参数
-XX:+UseSerialGC指定,最古老,最稳定以及效率高的收集器,新生代使用复制算法,老年代使用标记-压缩算法,单线程执行回收,SWT较长
- Serial Old收集器,采用单线程基于标记-整理算法并工作在老年代的收集器
- ParNew收集器,这是一个专用于新生代的收集器,也是个并行收集器,通过命令行参数
-XX:+UseParNewGC指定,通过命令行参数-XX:ParallelGCThreads指定回收线程的数量,使用复制算法
- Parallel收集器,并行算法,新生代复制算法、老年代标记-压缩算法,和ParNew相似,但更注重吞吐量,通过命令行参数
-XX:+UseParallelGC指定时老年代使用串行模式回收,通过命令行参数-XX:+UseParallelOldGC指定时老年代使用并行模式回收,还可通过-XX:MaxGCPauseMills限制停顿毫秒数,还可通过-XX:GCTimeRatio限制可以在GC上花费的时间比值
- CMS收集器,Concurrent Mark Sweep 并发标记清除(应用程序线程和GC线程交替执行)收集器,如名,使用标记-清除算法,CMS的设计决定了它拥有SWT低但是并发阶段也会略有降低的特点,这是一个用于老年代的收集器,通过命令行参数
-XX:+UseConcMarkSweepGC指定。当触发Full GC时会进行堆压缩(将仍然存活的对象移动到堆的其他区域,这样做有助于减少碎片)。JDK6、7及以前的时代,较多人以新生代使用ParNew收集器+老年代使用CMS的组合方式,效果还不错
- G1收集器,在JDK1.7中正式发布,采用标记整理算法,不会产生内存空间碎片,SWT较低,对G1来说,Java的内存布局虽然还保留新生代和老年代的概念,但是它是将Java堆划分成若干个大小相等的Region,然后当新生代的占用达到一定比例时进行回收,回收老年代时较多触发SWT,G1收集器还有一系列命令行选项控制它的工作参数
- ZGC收集器,JDK11新增,和G1一样,整堆统一处理,不区分新生代和老年代,设计目标是GC暂停时间不应超过10ms,处理堆的大小范围从MB级到TB级不等,仅支持64位系统,使用了彩色指针(Colored Pointer,又叫指针标记)和负载屏障(Load Barrier)两种新技术,还会压缩堆(将仍然存活的对象移动到堆的其他区域,这样做有助于减少碎片),像G1一样划分Region,但更加灵活
JDK1.5实现中,当老年代空间使用率达到68%时,就会触发CMS收集器,JDK1.6实现中,触发CMS收集器的阈值已经提升到92%,要是CMS运行期间预留的内存无法满足用户线程需要,会出现一次”Concurrent Mode Failure”失败,这是虚拟机会启动Serial Old收集器对老年代进行垃圾收集。
调优与故障排除
先介绍几个有用的命令行参数
- -XX:+PrintGC 输出GC日志
- -XX:+PrintGCDetails 输出GC的详细日志
- -XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
- -XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
- -XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
- -Xloggc:/logs/my_app/gc.log 将GC相关日志信息输出到指定的文件
经过实践的典型命令行配置:
-XX:NewSize=512m -XX:MaxNewSize=1024m -Xms512m -Xmx2048m -XX:MetaspaceSize=1024m -XX:MaxMetaspaceSize=2048m -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:+UseFastAccessorMethods -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:/logs/some-app/gc.log
正则表达式
正则表达式(Regular Expression)的理念最早源自数学领域,数学家们在解决数学问题的时候,会形成一个正则集,这个正则集本质上一些数学符号,这些数学符号形成的正则集可以用于描述神经网事件的模型,于是这个正则集的代数,就被称为正则表达式。
后来,Unix和C语言的创始人Ken Thompson将正则表达式的符号系统引入计算机科学中,用于表述对文本字符的查找、替换、匹配模型。在此之后,正则表达式在各种计算机编程语言和应用领域得到了非常广泛的应用和发展。
正则表达式中的元字符解释
| 元字符和常见模式语法(pattern) |
描述 |
例证 |
| \ |
转义字符。 |
\(,匹配左括号 |
| ^ |
匹配行首。 |
^a,匹配以字符a开头的行的内容,如果启用了Multiline属性,也匹配\r或\n之后的位置。 |
| $ |
匹配行尾。 |
z$,匹配以z结尾的行,如果启用了Multiline属性,也匹配\r\n之前的位置。 |
| * |
匹配前面的项任意次。 |
ab*,既匹配ab(*前面的字符0次),也匹配abb(*前面的字符1次),也匹配abbb(*前面的字符2次)。等价于{0,} |
| + |
匹配前面的项至少1次。 |
ab*,不匹配ab(因为*前面的字符是0次),匹配abb和abbb。等价于{1,} |
| ? |
匹配前面的项0次或1次。 |
abc?,匹配ab和abc。等价于{0,1} |
| {n} |
n是个非负数,匹配前面的项n次。 |
ab{1},匹配abb,但是不能匹配abbb。 |
| {n,} |
n是一个非负数,匹配前面的项至少n次。 |
ab{1,},匹配ab,同时能匹配ab后面再加任意个字符b。 |
| {n,m} |
n和m是非负数,n≤m,最少匹配n次,最多匹配m次。 |
ab{1,2},匹配abb、abbb,但是不能匹配abbbb(因为已经b已超过2次)。注意:{n,m}这个匹匹配式中没有空格。 |
| ? |
跟在其他限制符*、+、?、{n}、{n,}、{n,m}后面表示为非贪婪模式,非贪婪模式尽可能少的匹配。 |
以^abc??$匹配三行字符串abc、abcc、abccc时,只会匹配第一行的abc。因为^abc??$的意思是单行匹配、并且以a开头、a后面紧接着是bc,c后面有一个问号,表示c有0次或多次均可,此时还是3行都满足条件,再往右又有一个问号,表示非贪婪模式开启,那么就找c最少的,于是匹配得是第一行的abc。 |
| . |
英文句点,匹配除了换行符\r和\n之外的任意一个字符。 |
|
| | |
或匹配。 |
a|x可以匹配“abc”,但是不会匹配“def”。 |
| [ab] |
集合包含匹配。 |
[ax]可以匹配“abc”,但是不会匹配“def”。 |
| [^ab] |
集合不包含匹配。 |
[abc],表示只要包含了出现在集合中的字符都会匹配,[ax]可以匹配“abc”,也可以匹配“xyz”,但是不会匹配“def”。和前一条真好相反。 |
| [a-b] |
字符范围匹配。 |
[a-c],表示在a到c范围内的都会匹配,可以匹配“abc”,不会匹配“xyz”。 |
| [^a-b] |
字符范围不包含匹配。 |
[^a-c],表示只要不包含在a到c的字符都会匹配,不会匹配“abc”,可以匹配“xyz”,也可以会匹配“def”。和前一条正好相反。 |
| (pattern) |
以分组模式匹配并获取分组结果,分组结果在不同的编程语言中处理方法不同,但多数编程语言使用的方法是:分组中的第一个项是完整的匹配结果,从第二个项开始就是各分组。 |
^Windows (?:2000|XP|Vista|7|\8|10)$,分别匹配“Windows 2000”, “Windows XP”, “Windows Vista”, “Windows 7”, “Windows 8”, “Windows 10”都可以匹配到,并且会得到的分组数量为1,第一个匹配项是完整的匹配结果,例如Windows XP,第二个匹配项是分组结果XP。 |
| (?:pattern) |
以分组模式匹配但不获取分组结果,即虽然使用pattern进行分组匹配,但是对结果不分组。 |
^Windows (?:2000|XP|Vista|7|8|10)$,对于“Windows 98, Windows 2000, Windows XP, Windows Vista, Windows 7, Windows 8, Windows 10”中的“Windows 2000”、“Windows XP”、“Windows Vista”、“Windows 7”、“Windows 8”、“Windows 10”都可以匹配到。 |
| (?=pattern) |
以分组模式匹配但不获取分组结果,即虽然使用pattern进行分组匹配,但是对结果不分组,并且进行正向肯定预查。 |
^Windows (?=2000|XP|Vista|7|8|10).*$,对于“Windows 98, Windows 2000, Windows XP, Windows Vista, Windows 7, Windows 8, Windows 10”中的“Windows 2000”、“Windows XP”、“Windows Vista”、“Windows 7”、“Windows 8”、“Windows 10”都可以匹配到,但是只得到预查结果,即只会得到这6个匹配项中的“Windows”,不会得到匹配模式命中的目标字符。 |
| (?!pattern) |
以分组模式匹配但不获取分组结果,即虽然使用pattern进行分组匹配,但是对结果不分组,并且进行正向否定预查。 |
^Windows (?=2000|XP|Vista|7|8|10).*$,对于“Windows 98, Windows 2000, Windows XP, Windows Vista, Windows 7, Windows 8, Windows 10”中的“Windows 2000”、“Windows XP”、“Windows Vista”、“Windows 7”、“Windows 8”、“Windows 10”都可以匹配到,但是只得到预查结果的否定的结果,即除了命中的那6个项之外的剩下的“Windows 98”,同时也只会得到这一个“Windows”,同样不会得到匹配模式命中的目标字符。和前一条正好相反。 |
| (?<=pattern) |
以分组模式匹配但不获取分组结果,即虽然使用pattern进行分组匹配,但是对结果不分组,并且进行反向肯定预查。 |
(?<=[李王])小强,可以匹配“李小强”、“王小强”,但是不能匹配“张小强”、“刘小强”等等非姓李和姓王名叫小强的。 |
| (?<!pattern) |
以分组模式匹配但不获取分组结果,即虽然使用pattern进行分组匹配,但是对结果不分组,并且进行反向否定预查。 |
(?<![李王])小强,不能匹配“李小强”、“王小强”,但是可以匹配“张小强”、“刘小强”等等非姓李和姓王名叫小强的,和前一条正好相反。 |
Java中的正则表达式
Java中的正则表达式和其他编程语言中的正则表达式完全相同,主要用于解决两个方面的问题,一是检查给定的字符串是否符合预期(称为匹配),二是通过正则表达式,从指定的字符串中获得我们想要的信息。
关于正则表达式的教程,内容还是比较多的,就不在这里给大家介绍了,推荐大家一本书,有兴趣的同学可以看一下:

或者大家也可以去网上找找相关的资料,进行深入学习。本文主要给大家介绍在Java语言中如何应用正则表达式。
正则查找
正则查找,顾名思义,其实就是在目标字符串中寻找一定规则的数据。
简单查找:
package com.wasu.t.re;
import java.util.regex.Pattern;
/**
* 正则表达式查找
*
* @author lidawei
* @date 2021/11/29 18:15
*/
public class RegexFindDemo {
public static void main(String[] args) {
String s = "小明的年龄是18岁,正是学习的时候。";
Pattern pattern = Pattern.compile("\\d+");
System.out.println(pattern.matcher(s).find());
}
}
执行此代码,输出如下:
true
说明要找的数字到了。
多项查找:
package com.wasu.t.re;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 正则表达式查找2
*
* @author lidawei
* @date 2021/11/29 18:18
*/
public class RegexFindDemo2 {
public static void main(String[] args) {
String s = "小明、小强、小兴3个人,一个8岁,两个10岁,在院子里玩,虽然他们差2岁,但是他们玩的可开心了。";
Pattern pattern = Pattern.compile("\\d+");
Matcher matcher = pattern.matcher(s);
while (matcher.find()) {
System.out.println(matcher.group());
}
}
}
执行上述代码输出:
3
8
10
2
由此可知,find命令会对内容进行查找,每次调用find()时只要找到了,就返回true,没找到时返回false,所以这句话中的4个数字就都被找出来了。
这里还有一个反例,给大家看看:
package com.wasu.t.re;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 正则表达式匹配
*
* @author lidawei
* @date 2021/11/29 18:31
*/
public class RegexFindDemo3 {
public static void main(String[] args) {
String s = "我们与客户成功签约了,金额130万元,客户电话是13012345678";
Pattern pattern = Pattern.compile("1[3-5,7-9][0-9]\\d{4}\\d{4}");
Matcher matcher = pattern.matcher(s);
// 找出文章中的所有手机号
while (matcher.find()) {
System.out.println(matcher.group());
}
}
}
运行上述代码,会输出:
13012345678
由此可见,只要正则表达式写的好,就能够实现只找到自己想要找的数据,不会意外将其他数据找到,假如此例中将正则写成\d+,那么想要寻找手机号的逻辑就错误了。
正则验证
正则验证通常用于接口验证或参数验证,这里通常用到的是Matcher类,也就是整文匹配,请看示例代码:
package com.wasu.t.re;
import java.util.regex.Pattern;
/**
* 正则表达式匹配
*
* @author lidawei
* @date 2021/11/30 14:04
*/
public class RegexpMatchDemo {
public static void main(String[] args) {
String[] ss = new String[]{ "16899999912", "13900001111" };
Pattern mobilePattern = Pattern.compile("^1[3-5,7-9][0-9]\\d{4}\\d{4}$");
for (String s : ss) {
if (!mobilePattern.matcher(s).matches()) {
System.out.println(s + "不是有效的手机号码,请重新输入");
}
}
}
}
运行代码,得到输出如下:
16899999912不是有效的手机号码,请重新输入
在实践中,通常会将接口的入参验证机制做一些封装,比如定义一个注解,然后通过注解成员接收正则表达式,然后再通过拦截器对接口调用进行处理,在接口的入参位置定义一个Java类接收参数,然后在Java类的字段成员上通过注解定义校验规则。当有请求进来时,通过拦截器先解析参数和目标Java类的对应关系,然后通过目标Java类的注解参数获得注解值,取得验证规则,然后执行正则校验,如果成功,就放行,如果失败,就拒绝服务。这样就可以优雅地设计出与业务系统相对独立的、高效灵活的参数校验机制。事实上,Spring自带的参数校验,就是使用这种机制设计出来的,只不过人家做的比较复杂而已。
正则替换
正则替换通常用于实现普通的字符串替换无法实现的逻辑,比如最常见的,就是手机号码脱敏:
package com.wasu.t.re;
/**
* 使用正则表达式替换实现手机号码脱敏
*
* @author lidawei
* @date 2021/11/30 14:13
*/
public class RegexpReplaceDemo {
public static void main(String[] args) {
String[] mobiles = new String[]{"13012345678", "15699998888", "18966667777"};
for (String mobile : mobiles) {
// (?<=) 匹配但不保留
// (?=) 匹配并保留
// 所以这里正则的意思是:从左往右开始查找,先找到3个数字,不保留(忽略它),再继续找到4个数字,保留下来,将保留下来的数字替换成星号
String m = mobile.replaceAll("(?<=[\\d]{3})\\d(?=[\\d]{4})", "*");
System.out.println(mobile + "--> " + m);
// 使用括号分组,使用美元符号+数字($1、$2、$3...$n)对分组结果进行引用
String m1 = mobile.replaceAll("(\\d{3})(\\d{4})(\\d{4})", "$1****$2");
System.out.println(mobile + "==> " + m1);
}
}
}
运行代码,输出如下:
13012345678--> 130****5678
13012345678==> 130****1234
15699998888--> 156****8888
15699998888==> 156****9999
18966667777--> 189****7777
18966667777==> 189****6666
Java的String类中的replaceAll方法,第一个参数就是正则匹配串,所以它可以实现非常强大的替换功能,手机号腾敏只是众多应用案例之一。
常用正则表达式
这些正表达式应用很广泛,当然,也不全是我写的,是我从网上收集来的,供大家参考。
校验数字的表达式
- 数字:
^[0-9]*$
- n位的数字:
^\d{n}$
- 至少n位的数字:
^\d{n,}$
- m-n位的数字:
^\d{m,n}$
- 零和非零开头的数字:
^(0|[1-9][0-9]*)$
- 非零开头的最多带两位小数的数字:
^([1-9][0-9]*)+(.[0-9]{1,2})?$
- 带1-2位小数的正数或负数:
^(\-)?\d+(\.\d{1,2})?$
- 正数、负数、和小数:
^(\-|\+)?\d+(\.\d+)?$
- 有两位小数的正实数:
^[0-9]+(.[0-9]{2})?$
- 有1~3位小数的正实数:
^[0-9]+(.[0-9]{1,3})?$
- 非零的正整数:
^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
- 非零的负整数:
^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
- 非负整数:
^\d+$ 或 ^[1-9]\d*|0$
- 非正整数:
^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
- 非负浮点数:
^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
- 非正浮点数:
^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
- 正浮点数:
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
- 负浮点数:
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
- 浮点数:
^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
校验字符的表达式
- 汉字:
^[\u4e00-\u9fa5]{0,}$
- 英文和数字:
^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
- 长度为3-20的所有字符:
^.{3,20}$
- 由26个英文字母组成的字符串:
^[A-Za-z]+$
- 由26个大写英文字母组成的字符串:
^[A-Z]+$
- 由26个小写英文字母组成的字符串:
^[a-z]+$
- 由数字和26个英文字母组成的字符串:
^[A-Za-z0-9]+$
- 由数字、26个英文字母或者下划线组成的字符串:
^\w+$ 或 ^\w{3,20}$
- 中文、英文、数字包括下划线:
^[\u4E00-\u9FA5A-Za-z0-9_]+$
- 中文、英文、数字但不包括下划线等符号:
^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
- 可以输入含有^%&',;=?\"等字符:`[^%&',;=?\x22]+
12 禁止输入含有~的字符:[^~\x22]+`
其它
- 匹配除 \n 以外的任何字符:
.*
- 汉字:
[\u4E00-\u9FA5]
- 全角符号:
[\uFF00-\uFFFF]
- 半角符号:
[\u0000-\u00FF]
特殊需求表达式
- Email地址:
^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
- 域名:
[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
- Internet URL:
[a-zA-z]+://[^\s]* 或 ^https?://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
- 手机号码:
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
- 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):
^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
- 国内电话号码(0511-4405222、021-87888822):
\d{3}-\d{8}|\d{4}-\d{7}
- 身份证号(15位、18位数字):
^\d{15}|\d{18}$
- 短身份证号码(数字、字母x结尾):
^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$
- 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):
^[a-zA-Z][a-zA-Z0-9_]{4,15}$
- 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):
^[a-zA-Z]\w{5,17}$
- 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):
^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
- 日期格式:
^\d{4}-\d{1,2}-\d{1,2}
- 一年的12个月(01~09和1~12):
^(0?[1-9]|1[0-2])$
- 一个月的31天(01~09和1~31):
^((0?[1-9])|((1|2)[0-9])|30|31)$
- 中文字符的正则表达式:
[\u4e00-\u9fa5]
- 双字节字符 (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)):
[^\x00-\xff]
- 空白行的正则表达式(可以用来删除空白行):
\n\s*\r
- 腾讯QQ号(腾讯QQ号从10000开始):
[1-9][0-9]{4,}
- 中国邮政编码(中国邮政编码为6位数字):
[1-9]\d{5}(?!\d)
- IP地址(提取IP地址时有用):
\d+\.\d+\.\d+\.\d+
- IP地址:
((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))
- IP-v4地址(提取IP地址时有用):
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
- 校验IP-v6地址:
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
- 子网掩码:
((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))
- 校验日期(“yyyy-mm-dd“ 格式的日期校验,已考虑平闰年。):
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$
- 查找CSS属性:
^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1}
- 提取页面超链接:
(<a\\s*(?!.*\\brel=)[^>]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^" rel="external nofollow" ]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)>
- 提取网页图片:
\\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*)
- 提取网页颜色代码:
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$
- 文件扩展名效验:
^([a-zA-Z]\\:|\\\\)\\\\([^\\\\]+\\\\)*[^\\/:*?"<>|]+\\.txt(l)?$
- 判断IE版本:
^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$
JDBC
JDBC是Java Data Base Connectivity的简写,即:Java数据库连接,JDBC是一套规范,它规定了Java语言访问数据库的方式,但是具体的不同数据库的不能使用,它没有定义,由各数据库厂商提供数据库驱动完成。你可以理解为:JDBC仅仅是一套接口,没有实现,这套接口的实现是各数据库厂商提供的。这样做的好处是Java语言和不同的数据库无关,完全解耦,但是又能支持众多的数据库访问操作。
!> 本教程以市面上应用非常广泛的MySQL为例进行主角,并且假定同学们已经具备一些基础的数据库增删改查的操作技能,包括简单的表连接操作等。如果大家对此还有欠缺,应当先学习数据库,然后才能继续下面的课程。

JDBC API提供以下接口和类
DriverManager:此类管理数据库驱动程序列表。 使用通信子协议将来自java应用程序的连接请求与适当的数据库驱动程序进行匹配。在JDBC下识别某个子协议的第一个驱动程序将用于建立数据库连接。Driver:此接口处理与数据库服务器的通信。我们很少会直接与Driver对象进行交互。 但会使用DriverManager对象来管理这种类型的对象。 它还提取与使用Driver对象相关的信息。Connection:此接口具有用于联系数据库的所有方法。 连接(Connection)对象表示通信上下文,即,与数据库的所有通信仅通过连接对象。Statement:使用从此接口创建的对象将SQL语句提交到数据库。 除了执行存储过程之外,一些派生接口还接受参数。ResultSet:在使用Statement对象执行SQL查询后,这些对象保存从数据库检索的数据。 它作为一个迭代器并可移动ResultSet对象查询的数据。SQLException:此类处理数据库应用程序中发生的任何错误。
JDBC实践
首先,让我们通过Maven创建一个Java工程,对Maven管理Java工程不熟悉的同学,请移步Maven实战章节继续学习,工程创建好之后,在项目的pom.xml中的dependencies节点下添加MySQL的驱动依赖,如下所示:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.26</version>
</dependency>
我们先创建一个test数据库,再创建一张tb_user表,填几条数据,如下所示:

通过JDBC+MySQL驱动实现简单查询:
package com.wasu.t.db;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
/**
* JDBC简单示例
*
* @author lidawei
* @date 2021/11/30 14:50
*/
public class JdbcDemo {
public static final String URL = "jdbc:mysql://localhost:3306/test";
public static final String USER = "www";
public static final String PASSWORD = "123456";
public static void main(String[] args) throws Exception {
//1.加载驱动程序
Class.forName("com.mysql.cj.jdbc.Driver");
//2. 获得数据库连接
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
//3.操作数据库,实现增删改查
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT id, name, age FROM tb_user");
//如果有数据,rs.next()返回true
System.out.printf("%10s%20s%10s\n", "id", "name", "age");
while(rs.next()){
System.out.printf("%10d%20s%10d\n", rs.getInt("id"), rs.getString("name"), rs.getInt("age"));
}
}
}
运行代码得到以下输出:
id name age
1 wang 18
2 zhang 22
3 zhao 23
JDBC应用
JDBC虽然是Java应用访问数据库的基础,但是在实践中却很少直接使用它,原因是像访问数据库这种操作,必须要实现池化技术,既:创建一个连接池,然后把数据库的连接信息放到池中,然后对它们进行管理,维护这个池中连接的最小多个、最大多少,空闲多久回收等等,只有这样,才能真正实现高效地访问数据库。
所以,大家对JDBC的内容只要大体上了解就差不多了。唯一要注意的就是事务的问题。事务不是Java语言的特性,而是关系型数据库(如MySQL、Oracle等)的特性,这个特性能够保证数据库数据的一致性,举例:一个简化版的电商系统的数据库,有用户信息表、商品信息表、订单信息表、物流信息表、优惠券信息表等,当用户下单之后,我们要在用户表中更新它的购买信息,在商品表中更新它的库存信息,在订单表中插入新订单,在物流信息表中插入发货信息,在优惠券信息表中更新使用信息等等,这一连串的操作,必须做到要么全部成功,要么全部失败,绝对不可以部分成功部分失败,道理很简单,假如商品库存减少操作成功了,但是订单插入操作失败了,物流信息却又创建了,这不是乱套了吗?所以要用事务的方式保证这一批操作同时成功,如果失败,要么提示用户,要么在预先约定的地方记录下来让技术人员进一步排查解决。
MySQL是通过START TRANSACTION;开启事务,通过commit;提交事务,再通过ROLLBACK;回滚事务的方式进行的。如果仅仅是一张表的操作,不必开启事务,成功失败即刻得知。如果是多张表,通常的操作步骤是这样的:
1. 执行START TRANSACTION;开启事务
2. 分别对各表进行insert和update操作,在这里,虽然我们可以看到这些语句操作成功了,但是不会立即更新到数据库中的
3. 执行commit;提交事务,当然,如果第2步的某些步骤出现了错误,那么这一步就不是提交,而是通过ROLLBACK;回滚事务,撤销刚才的操作。
在Java中,对事务的控制大致是这样的:
try{
//1.加载驱动程序
Class.forName("com.mysql.cj.jdbc.Driver");
//2. 获得数据库连接
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
conn.setAutoCommit(false);//开启事务
String sql = "update tb_user set age = 20 where id = 1";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.executeUpdate();
conn.commit();//走到这一行还没有报错,说明没问题了,提交事务
} catch (Exception e) {
conn.rollback();//出现异常了,回滚事务
}
再写一个多表操作的例子:
package com.wasu.t.db;
import java.sql.*;
/**
* JDBC控制事务
*
* @author lidawei
* @date 2021/11/30 15:16
*/
public class JdbcTransactionDemo {
public static final String URL = "jdbc:mysql://localhost:3306/test";
public static final String USER = "www";
public static final String PASSWORD = "123456";
public static void main(String[] args) throws SQLException {
Connection conn = null;
try {
//1.加载驱动程序
Class.forName("com.mysql.cj.jdbc.Driver");
//2. 获得数据库连接
conn = DriverManager.getConnection(URL, USER, PASSWORD);
//开启事务
conn.setAutoCommit(false);
// 开始第一步操作
String sql = "update tb_user set age = 20 where id = 1";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.executeUpdate();
// 开始第二步操作
sql = "update tb_role set name = '超级管理员' where name = '系统管理员'";
pstmt = conn.prepareStatement(sql);
pstmt.executeUpdate();
//走到这一行还没有报错,说明没问题了,提交事务
conn.commit();
} catch (Exception e) {
conn.rollback();//出现异常了,回滚事务
}
}
}
JDBC控制事务,保证了数据的一致性,但是它有新的问题出现,就是脏读、不可重复读、幻读等,这都属于高级话题了,大家有空可以先自行学习,这里就不讲了。
lambda表达式
lambda表达式是许多编程语言中都有的一个特性,它的核心思想是“匿名函数”,通常情况下,我们对一组功能,都要定义一个函数将这些功能放到函数中,然后在需要的时候进行调用。但是这有一个问题,那就是这是服务提供方做的事情,许多时候,这个事情是需要让服务的使用方去做的。
举例:一个框架提供了字符串打印功能,但是具体怎么打印,不可能框架定义的能满足所有人的需求,那就必须要提供一个机制,让使用框架的人能够定义字符串具体怎么打印。此时,按照一般的编程思想,那就框架提供一个接口,然后框架中调用接口方法,在框架具体使用的时候,使用框架的人针对接口提供一个实现类,这样就可以满足“让使用框架的人定义字符串具体怎么打印”这样的需求了。
传统的做法如下:
package com.wasu.t.lambda;
import java.util.ArrayList;
import java.util.List;
/**
* Lambda表达式的最主要的作用,就是简化对接口实现类的写法
*
* @author lidawei
* @date 2022/8/14 10:39
*/
public class LambdaDemo1 {
/**
* 这里定义一个接口,它的作用是对给字的字符串数组进行很友好的输出
*/
interface friendlyOutputable {
void output(List<String> ss);
}
public static void main(String[] args) {
List<String> names = new ArrayList<String>(){{
add("张三");
add("李四");
add("王五");
}};
// 传统写法
friendlyOutputable fo = new friendlyOutputable() {
@Override
public String output(List<String> ss) {
System.out.print("[");
for (String s : ss) {
System.out.print(s + ", ");
}
System.out.print("\b\b] ");
}
};
fo.output(names);
}
}
代码中,当我要使用这个接口的时候,我自己给它提供一个实现类,就可以了。其实如果读者有开发经验,是经常会看到这种代码的。它有一个缺点,其实代码比较冗余,那有什么办法简化呢?如下所示:
package com.wasu.t.lambda;
import java.util.ArrayList;
import java.util.List;
/**
* Lambda表达式的最主要的作用,就是简化对接口实现类的写法
*
* @author lidawei
* @date 2022/8/14 10:39
*/
public class LambdaDemo1 {
/**
* 这里定义一个接口,它的作用是对给字的字符串数组进行很友好的输出
*/
interface friendlyOutputable {
void output(List<String> ss);
}
public static void main(String[] args) {
List<String> names = new ArrayList<String>(){{
add("张三");
add("李四");
add("王五");
}};
// lambda写法
friendlyOutputable fo = ss -> {
System.out.print("[");
for (String s : ss) {
System.out.print(s + ", ");
}
System.out.print("\b\b] ");
};
fo.output(names);
}
}
你注意看,new friendlyOutputable()实例化一个接口(姑且这么讲,事实上接口是不可以被实例化的,这其实就是new一个匿名类)时,要实现它的方法,就将此处的代码改写成为一个箭头函数了,这就是lambda表达式,不过要注意的是 :通过这种匿名内部类改写为lambda表达式时,如果接口中有多个参数,要用括号括起来。
Java中线程的机制就是这样设计的,JDK在开发的时候,设计了一套线程机制,但是线程具体做什么,是由具体的业务方来确定的,所以,它就提供了一个java.lang.Runnable接口,很多时候我们创建一个线程的时候,都会要么定义一个实体类实现这个接口,要么定义一个匿名类实现这个接口,道理都是相通的。
所以,lambda表达式最主要的作用,就是简化代码写法,优化那些很冗余的东西,让它们看起来很优雅。
lambda表达式还有更简洁的用法,等我们学习了后面的方法引用和构造器引用之后,再进一步加强和巩固。
函数式接口
函数式接口的核心是一个java.lang.FunctionalInterface,去JDK中看它的定义,你会发现它其实是一个注解。在JDK8中,如果一个接口上加上了这个注解,那么它就是一个函数式接口,你再仔细研究这些个接口,比如我们非常常见的java.lang.Runnable和java.util.concurrent.Callable,如果你仔细研究引用了这个函数式接口注解的这些接口,你会发现它们有一个共同的特点,那就是这些接口有且只有一个抽象方法(事实上Oracle官方也是这么定义)。
学过注解我们知道,注解其实只是对代码有一些附加作用,你在代码中用它,它就有作用,不用它,它就不起使用。而这一次,JDK8将这个注解的作用发挥了起来,它在编译代码时,会检查我们代码中引用函数式接口时是否存在问题,或者我们自己定义函数式接口时是否也存在问题。
函数式接口的主要功能,是也是简化代码。我们接着改造前面的友好打印字符串的代码,如下所示:
package com.wasu.t.lambda;
import java.util.function.BiFunction;
import java.util.function.Function;
/**
* @author lidawei
* @date 2022/8/14 10:39
*/
public class LambdaDemo2 {
/**
* 这里定义一个接口,它的作用是对给字的字符串数组进行很友好的输出
*/
@FunctionalInterface
interface calc {
int add(int a, int b);
}
public static void main(String[] args) {
// 以lambda写法,对函数式接口更加友好
calc c = (a, b) -> a + b;
int r = c.add(1, 2);
System.out.println(r);
// 不需要我们自己预先定义接口了,可以直接定义代码实现形式
// 原因是java.util.function.Function是JDK8中预先好的,泛型中第一个类型是参数类型,第二个类型是返回值类型
// JDK的开发团队帮我们做了预先定义接口这件事情,而他们定义的接口是泛型的,适用性很广
Function<Integer, Integer> twice = n -> n + n;
// 输出4,apply方法也是java.util.function.Function中预先定义好的
System.out.println(twice.apply(2));
// 再看一例,两个参数的,下面的java.util.function.BiFunction和上面的java.util.function.Function一样,也是JDK中预定义好的
BiFunction<Integer, Integer, Integer> mySum = (a, b) -> a + b;
// 输出30
System.out.println(mySum.apply(10, 20));
}
}
其实本质上和前一章节的lambda表达式并无区别,只是我们不必再自己定义了,JDK8中帮助我们预定义了,我们直接使用即可。具体去看一下java.util.function.Function的定义就马上明白了。
需要注意的是:函数式接口的定义和调用是两个步骤,在上述代码中,执行Function<Integer, Integer> twice = n -> n + n;这段代码时,不会立即求表达式的值(事实上这个时候也只是预置代码,因为这个时候你还不知道n的值是多少),真正使得这段代码被执行,是在代码twice.apply(2)这里。
换个角度理解:函数式接口的逻辑是这样的,遇到Function<Integer, Integer> twice = n -> n + n;时,JVM会将这段代码逻辑确定下来,具体逻辑是:它有一个Integer类型的入参和Integer类型的返回值,代码逻辑是对入参进行一次累加(当然在这里也可以有更加复杂的业务逻辑),遇到twice.apply(2)时,JVM会将传入的Integer类型的数据2传给前面的代码Function<Integer, Integer> twice = n -> n + n;去执行,于是得到4。为了验证我们的理解是否正确,我们再写一段代码,如下所示:
package com.wasu.t.lambda;
import java.util.function.Function;
/**
* @author lidawei
* @date 2022/8/14 10:39
*/
public class LambdaDemo21 {
public static void main(String[] args) {
System.out.println("预定义");
Function<Integer, Integer> twice = n -> {
System.out.println("表达式1");
Integer dv = n + n;
System.out.println("表达式2");
return dv;
};
System.out.println("准备调用");
Integer value = twice.apply(2);
System.out.println("得到值,输出");
System.out.println(value);
System.out.println("完成");
}
}
执行上述代码,输出以下内容:
预定义
准备调用
表达式1
表达式2
得到值,输出
4
完成
对照代码和输出,我们很容易得出一个前面的结论:先定义一个lambda表达式形式的代码块,把它赋给函数式接口java.util.function.Function,然后再在需要的地方调用这个函数式接口的方法以执行lambda表达式形式的代码块,这是两个步骤。
再换一个角度理解:
- 在以前,我们以匿名内部类的方式写一段代码,把这段代码赋给一个接口(比如
java.lang.Runnable),然后在需要的地方调用这个接口的方法,这段代码就会被执行(比如调用线程的java.lang.Runnable#run方法)。
- 现在,我们以lambda表达式的方式写一段代码,把这段代码赋给一个函数式接口(函数式接口仍然是个接口,比如
java.util.function.Consumer),然后在需要的地方调用这个接口的方法,这段lambda表达式形式的代码就会被执行(比如java.util.function.Consumer#accept方法)。
所以,我们按下面的步骤来理解函数式编程的本质:
- 函数是什么?函数是一些事物和另外一些事物的映射关系,比如2和8这两个数字的映射关系是2的3次方得到8,那么它们就是函数。在这个定义中,一些事物我们称之为输入,另外一些事物我们称之为输出。简单地理解:如果输入2,会得到8,那么函数所体现的映射关系是:对输入的数字,求它的3次方,我们姑且称之为立方函数。所以,从计算机的角度理解,你可以认为函数其实就是一个计算过程。
- 函数本身也是一个对象(虽然有可能这个事物之间的映射关系会很复杂)。
- 函数可以嵌套,一个函数本身可以成为另一个函数的输入,也可以成为另一个函数的输出。这个略有复杂,还如上面的例子,我们的函数的输入不是2,而是一个加法函数,此加法函数的定义是输入两个数,求它们的和,具体表现为:输入1和1,得到2,那么现在立方函数的输入就不必再是单纯的数字了,它可以是一个加法函数。其他情况依此类推。需要提一下的是,这么做虽然略显复杂,但是它其实已经是对现实世界的最好建模和体现了,因为现实世界就是这样的,一件事物本身是由多个其他事物构成的,而这件事物本身又是另外的事物的构成部分,无数这样庞大而复杂的事物,就构成了整个客观世界。
- 以这种定义和使用函数的思想进行计算机编程,就是函数式编程。
- 理论上,函数式编程有一个特点,它的输入和输出的这种映射关系(也就是函数)它是确定的,例如,对于立方函数来说,你输入2,你永远会得到8,无效你尝试多少次,都是这样的,而且它不需要变量,因为这种将一个计算过程封装成一个函数的编程方法,它的核心思想是面向计算的,给个输入,给你输出,用数学的问题帮助你解决所有问题。当然了,许多编程语言实现了函数式编程,但是现实情况总是复杂的,有时候我们也需要一些变量,所以很多编程语言在实现函数式编程的时候,都又提供了定义变量的功能(如Python、Javascript、Java8+等)。
- 将函数本身作为对象传给另外一个函数,这就叫高阶函数。
- 将一个函数本身作为这个函数的返回值返回出去,让这个函数的使用方得到一个函数而不是一个确定的值,这就叫闭包。
- 直接将一段计算过程(也就是计算机编程语言的代码)写成一个函数,以适当的方式保存起来,在需要的时候直接用,这个过程如果没给这个函数起一个确定的名字,就称之为匿名函数。
现在,您必须完全理解和掌握上述思想,才能在后面的函数式编程中(在JDK8中就是应用函数式接口进行编程)得心应手。
那么,JDK8中都帮我们预定义了哪些函数式编程的支持接口和功能呢?请看下面的表格:
| 序号 |
接口 |
描述 |
| 1 |
BiConsumer |
代表了一个接受两个输入参数的操作,并且不返回任何结果 |
| 2 |
BiFunction |
代表了一个接受两个输入参数的方法,并且返回一个结果 |
| 3 |
BinaryOperator |
代表了一个作用于于两个同类型操作符的操作,并且返回了操作符同类型的结果 |
| 4 |
BiPredicate |
代表了一个两个参数的boolean值方法 |
| 5 |
BooleanSupplier |
代表了boolean值结果的提供方 |
| 6 |
Consumer |
代表了接受一个输入参数并且无返回的操作 |
| 7 |
DoubleBinaryOperator |
代表了作用于两个double值操作符的操作,并且返回了一个double值的结果。 |
| 8 |
DoubleConsumer |
代表一个接受double值参数的操作,并且不返回结果。 |
| 9 |
DoubleFunction |
代表接受一个double值参数的方法,并且返回结果 |
| 10 |
DoublePredicate |
代表一个拥有double值参数的boolean值方法 |
| 11 |
DoubleSupplier |
代表一个double值结构的提供方 |
| 12 |
DoubleToIntFunction |
接受一个double类型输入,返回一个int类型结果。 |
| 13 |
DoubleToLongFunction |
接受一个double类型输入,返回一个long类型结果 |
| 14 |
DoubleUnaryOperator |
接受一个参数同为类型double,返回值类型也为double 。 |
| 15 |
Function |
接受一个输入参数,返回一个结果。 |
| 16 |
IntBinaryOperator |
接受两个参数同为类型int,返回值类型也为int 。 |
| 17 |
IntConsumer |
接受一个int类型的输入参数,无返回值 。 |
| 18 |
IntFunction |
接受一个int类型输入参数,返回一个结果 。 |
| 19 |
IntPredicate |
接受一个int输入参数,返回一个布尔值的结果。 |
| 20 |
IntSupplier |
无参数,返回一个int类型结果。 |
| 21 |
IntToDoubleFunction |
接受一个int类型输入,返回一个double类型结果 。 |
| 22 |
IntToLongFunction |
接受一个int类型输入,返回一个long类型结果。 |
| 23 |
IntUnaryOperator |
接受一个参数同为类型int,返回值类型也为int 。 |
| 24 |
LongBinaryOperator |
接受两个参数同为类型long,返回值类型也为long。 |
| 25 |
LongConsumer |
接受一个long类型的输入参数,无返回值。 |
| 26 |
LongFunction |
接受一个long类型输入参数,返回一个结果。 |
| 27 |
LongPredicate |
R接受一个long输入参数,返回一个布尔值类型结果。 |
| 28 |
LongSupplier |
无参数,返回一个结果long类型的值。 |
| 29 |
LongToDoubleFunction |
接受一个long类型输入,返回一个double类型结果。 |
| 30 |
LongToIntFunction |
接受一个long类型输入,返回一个int类型结果。 |
| 31 |
LongUnaryOperator |
接受一个参数同为类型long,返回值类型也为long。 |
| 32 |
ObjDoubleConsumer |
接受一个object类型和一个double类型的输入参数,无返回值。 |
| 33 |
ObjIntConsumer |
接受一个object类型和一个int类型的输入参数,无返回值。 |
| 34 |
ObjLongConsumer |
接受一个object类型和一个long类型的输入参数,无返回值。 |
| 35 |
Predicate |
接受一个输入参数,返回一个布尔值结果。 |
| 36 |
Supplier |
无参数,返回一个结果。 |
| 37 |
ToDoubleBiFunction |
接受两个输入参数,返回一个double类型结果 |
| 38 |
ToDoubleFunction |
接受一个输入参数,返回一个double类型结果 |
| 39 |
ToIntBiFunction |
接受两个输入参数,返回一个int类型结果。 |
| 40 |
ToIntFunction |
接受一个输入参数,返回一个int类型结果。 |
| 41 |
ToLongBiFunction |
接受两个输入参数,返回一个long类型结果。 |
| 42 |
ToLongFunction |
接受一个输入参数,返回一个long类型结果。 |
| 43 |
UnaryOperator |
接受一个参数为类型T,返回值类型也为T。 |
以上表格内容也不必全都记住,放在这里备查就行了,我们需要掌握的是,它们也很常用很好用的。
现在,我们要问一个问题,既然最开始的Java中的匿名内部类也能够解决问题(将一段代码封装成一个函数,然后在需要的时候调用它),那为什么还需要JDK8中的这一整套这么多的函数式接口呢?
对此,我的理解和答案是:对于一些功能来说,我们使用匿名内部类没有问题,比如使用匿名内部类实现java.lang.Runnable接口,弄一个线程运行一下,再比如输入小写字母得到大写,为什么没问题?因为JDK中已经提供了相应的方法,但是对于一些功能来说,就有问题了,比如当用户输入一个值的时候,我要对它进行较为复杂的加工,然后再返回,比如math库中提供了sin函数使得我可以求正弦,但是如果我要求3倍正弦值然后再求绝对值呢?我就得自己再定义一个接口,然后再基于这个接口写一个匿名内部类作为它的实现(别跟我说把math中的sin函数调3次,然后分别再去求绝对值,这么干的人大概率会被其他工程师diss,至少我不愿意成为这样的人)。再比如给一个列表,然后要按某个条件进行过滤筛选呢?最困难的是,某些东西在写代码的时候我只知道它的大概逻辑,不知道它的精确逻辑,比如我已经确定我要写一个用户列表的筛选功能,但是按什么筛?怎么筛?现在还不清楚,要让调用我代码的人去做,对于此类给定一个输入,通过各种还不知道或者即使知道还是存在很多变数的经过一堆的^@@#%^&*():">}{_((*&%^$%的操作得到一个输出的行为,就很有必要进行统一的抽象和封装了。这就是JDK8提供上面这一堆函数式接口的最大用意。归根结底,还是为了简化代码,提高编程效率,降低编程成本。
最后我再举一个例子,仍然是前章节的需求:我要用很友好的方式打印字符串列表,代码如下所示:
package com.wasu.t.lambda;
import java.util.ArrayList;
import java.util.List;
import java.util.function.Consumer;
/**
* Lambda表达式结合函数式接口,代码会简洁很多
*
* @author lidawei
* @date 2022/8/14 11:49
*/
public class LambdaDemo3 {
public static void main(String[] args) {
List<String> names = new ArrayList<String>(){{
add("张三");
add("李四");
add("王五");
}};
Consumer<List<String>> fo = ss -> {
System.out.print("[");
for (String s : ss) {
System.out.print(s + ", ");
}
System.out.print("\b\b] ");
};
fo.accept(names);
}
}
怎么样? ,我不必自己再去定义一个函数写匿名内部类了,JDK8中现成的函数模型Consumer拿来用一下即可,代码是不是更简洁了?!
方法引用与构造器引用
什么是方法引用
方法引用,其实就是将一个方法作为另外一个方法的参数传进去使用。
对象::实例方法名称
这是根据实例获得它的信息的方式(其实我感觉用的并不多):
package com.wasu.t.lambda;
import java.util.function.IntSupplier;
/**
* 方法引用:实例方法应用
*
* @author lidawei
* @date 2022/8/17 12:56
*/
public class LambdaDemo8 {
public static void main(String[] args) {
String s = "123";
IntSupplier fo = () -> s.length();
System.out.println(fo.getAsInt());
}
}
类名::静态方法名称
不需要实例化即可获得,如下所示:
package com.wasu.t.lambda;
import java.util.function.Supplier;
/**
* 方法引用:静态方法应用
*
* @author lidawei
* @date 2022/8/17 12:56
*/
public class LambdaDemo9 {
public static void main(String[] args) {
Supplier<Long> fo = System::currentTimeMillis;
System.out.println(fo.get());
}
}
类名::实例方法名称
不需要实例化类即可完成它的实例的方法调用,这个很简单,看下面的代码:
package com.wasu.t.lambda;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.function.UnaryOperator;
/**
* 方法引用:实例方法应用
*
* @author lidawei
* @date 2022/8/17 12:56
*/
public class LambdaDemo7 {
public static void main(String[] args) {
Function<String, Integer> fo = String::length;
System.out.println(fo.apply("hello"));
}
}
就是引用了String类下的length方法而已。
构造器引用
由于构造器的名称和类名完全一样,所以可以使用类名::new的方法简写,先看下面的代码:
package com.wasu.t.lambda;
import java.util.function.Consumer;
/**
* 基于Lambda表达式的构造器引用
*
* @author lidawei
* @date 2022/8/17 12:56
*/
public class LambdaDemo5 {
public static void main(String[] args) {
Consumer<String> fo = (String name) -> {
new MyClass(name);
};
System.out.println("1");
fo.accept("hello");
System.out.println("2");
}
private static class MyClass {
public MyClass(String name) {
System.out.println(name);
}
}
}
在这里,我们使用Consumer这个函数式接口时,给它的代码实现是一个lambda表达式,在lambda表达式代码块中,创建一个MyClass的实例。请注意Consumer这个函数式接口的使用方法,下面我们改造这段代码如下:
package com.wasu.t.lambda;
import java.util.function.Consumer;
/**
* 基于Lambda表达式的构造器引用
*
* @author lidawei
* @date 2022/8/17 12:56
*/
public class LambdaDemo6 {
public static void main(String[] args) {
Consumer<String> fo = MyClass::new;
System.out.println("1");
fo.accept("hello");
System.out.println("2");
}
private static class MyClass {
public MyClass(String name) {
System.out.println(name);
}
}
}
执行这段代码得到输出:
1
hello
2
总结:构造器引用可以看作是方法引用的一种特例。
Stream流
先回顾一下迭代
我们之前已经学习研究过我循环处理的用法了,这其实就是一个迭代的过程,即:一步一步的做事情,逐步推进,直至完成。如下所示:
package com.wasu.t.stream;
/**
* 常规迭代
*
* @author lidawei
* @date 2021/8/12 18:22
*/
public class Jdk8StreamDemo1 {
public static void main(String[] args) {
Integer[] numbers = new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int sum = 0;
for (Integer number : numbers) {
sum += number;
}
System.out.println("sum:" + sum);
}
}
还有一种写法:
package com.wasu.t.stream;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* 常规迭代
*
* @author lidawei
* @date 2021/8/12 18:22
*/
public class Jdk8StreamDemo2 {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
int sum = 0;
Iterator<Integer> iterator = numbers.iterator();
while (iterator.hasNext()) {
sum += iterator.next();
}
System.out.println("sum:" + sum);
}
}
这些代码的共同特点是:做事情一步一步推进,直至完成。同时,它们还有另外一个特点:每迭代一次,sum的值就会即时变化,换句话说,每个操作步骤的结果会立即得到反馈。
什么是流?
流就像水流式一样,将若干个步骤逐个执行,它其实也是一种迭代,即:做完一件事情的若干个步骤,但是它比前面说的迭代要复杂的多,主要体现在两个方面:
- 前一个操作步骤的结果,通过通道传递给下一个操作,然后由最终操作获得前面的处理结果
- 除了最终操作,前面的这些若干个步骤,是可以并行的
下面,我们以需求: 求1到10的所有数字的和 为例,说一下它们的具体原理体现:
- 传统的循环迭代模式,每迭代一次,是将当前正在迭代的数字累加到sum变量中去,所以,sum变量声明在迭代代码块外部,用来辅助求值的,循环体就是操作步骤。
- 流式操作模式,是将每个操作都抽象成为函数式接口,这些函数式接口就代表了用户操作,所以,流的执行过程,就是解释执行这些函数式接口的过程。
相比于传统的循环操作模式,JDK8中的流(Stream)对代码的分解和封装明显更好,更优雅。
再以一个案例说明一下,需求:从一组数字中找到奇数:
- 用传统的循环模式,在循环外面定义一个列表,用于收集结果,在循环体中,逐项分析处理每一个数字,遇到符合要求的,放到结果列表中,循环完成,得到结果
- 用流的处理模式,给一个数字判断这个数字是否是奇数这样的操作,是可以被反复使用的,将它封装成一个函数式接口,流的每个数字到达这个函数式接口,都被函数式接口处理一遍,不符合条件,丢弃它,符合条件了,将结果通过通道向下传递,最终将符合条件的所有数字收集起来保存到结果列表中
总结:可以看出,虽然最终结果是一样的,但是编程的思想和方法是不一样的,传统的循环模式,是一种命令式编程,我定义了若干个步骤,让计算机来执行,然后我自己决定如何收集结果以完成我的目标,流式编程,是我根据业务需求声明了一个能够达成目标的方法,将该方法放到流中,让计算机以流式操作数字集,在此过程中,数字被逐个放进我的方法中来执行,最后帮助我收集最终我想要的结果(当然了,帮助我收集结果的操作也是一个预先声明好的方法,只不过是JDK声明的而不是我们程序员)。所以,传统的编程方式是命令式编程,而流式操作,其实是声明式编程。
当然了,对于命令式编程和声明式编程的优劣,业界向来争论不休,在我看来,它们应该应该是这样的:
- 命令式编程相对于大规模、超大模型的业务系统来说,实现起来太过繁琐和复杂,因为这要求软件开发人员考虑到业务中的每一个环节和细节,然后写出代码(也就是指令)让计算机去处理和执行,从这个角度讲,软件开发人员的心智负担较重
- 命令式编程,可以通过命令对计算机的每一个操作和行为进行精确的控制和调度,这在某些业务场景中还是非常实用的
- 声明式编程,更多的是从业务的角度考虑问题,将一些要做的事情声明成函数,然后让计算机在应当调用它们的时候调用它们得到结果,这对于组织大规模、超大规模的业务的业务系统是非常有利的,也能最大限度的复用函数,但是缺点也很明显,抽象层次更高,系统初期在设计阶段的投入也就更高了
- 声明式编程,更多的一种思想是:要做的事情的方法,我声明好了,你去办吧。
- 命令式编程,更多的一种思想是:我们要做某件事情,我现在告诉你步骤是一二三,路途出现问题的处理方法是一二三,全都给你定义好了,你去照本宣科执行一遍即可。
- 声明式编程,在一些业务场景中非常常用,比如我开发一套GUI程序,声明好了它的很多按钮和相应点击行为,当用户点击某按钮时,计算机就去执行声明好的函数,做相应的事情就好了。这里和命令式编程有一个非常重要的区别是:我预先声明的众多按钮和点击行为,什么时间哪个按钮被点击做什么事情,在编码阶段开发人员是不知道的,这取决于用户。
- 命令式编程,在一些系统底层非常常用,比如我要开发自动化测试软件,我针对A类数据,定义好它的操作步骤是从a_step1到a_step5,针对B类数据,定义好它的操作步骤是从b_step1到b_step3,现在我要做自动化测试,我就准备好A类数据,让计算机按我明确的指定去从a_step1到a_step5执行一遍,然后我去看看执行结果如何,再准备好B类数据,依同样的方法操作一遍。这样我的自动化测试就完成了。这里和声明式编程的一个非常重要的区别是:我编写测试脚本时,我很清楚A数据的优先级更高,所以我先准备它的数据让它对应的a_step1到a_step5执行一遍。整个过程的步骤和命令在编码阶段开发人员是非常明确和确定的。
- 是以,从程序员的角度讲,命令式编程重在逻辑控制,过程严密、步骤精细,这种程序便于调试和排除问题,而声明式编程的抽象层次更高,重在事件响应,通常基于事件状态处理响应和回调。所以,一般来说,命令式编程工作量大但易于维护,声明式编程工作量相对小但难以维护,大家在平时的软件系统设计和开发时,也要考虑这些因素,毕竟,据说业内前辈做过统计,写代码的时间只有20%,维护和修改各类问题以及迭代新需求的时间占了80%。
流的使用
创建流
package com.wasu.t.stream;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.stream.IntStream;
import java.util.stream.Stream;
/**
* 创建流的几种常见方式
*
* @author lidawei
* @date 2021/8/12 18:22
*/
public class Jdk8StreamDemo4 {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
// 基于List创建流
Stream<Integer> integerStream1 = numbers.stream();
// 基于多个值使用静态of方法创建流
Stream<Integer> integerStream2 = Stream.of(1, 2, 3, 4, 5);
// 基于数组创建流
int[] a = {1, 3, 5, 6, 8};
IntStream stream = Arrays.stream(a);
// 使用方法生成流,这里的方法我们使用了Math类中的random方法,你也可以自己写一个自己的方法在这里调用
Stream<Double> doubleStream = Stream.generate(Math::random).limit(3);
}
}
在实践中,根据我的经验,用的最多是根据List创建流。
流式计算
遍历、过滤和查找
package com.wasu.t.stream;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Optional;
import java.util.stream.IntStream;
import java.util.stream.Stream;
/**
* 使用流进行遍历、过滤和查找
*
* @author lidawei
* @date 2021/8/12 18:22
*/
public class Jdk8StreamDemo5 {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
// 进行遍历,在这里引用了我们自己定义的方法
numbers.stream().forEach(IntegerPrinter::print);
// 过滤,找出列表中的所有偶数,然后打印出来
numbers.stream().filter(n -> n % 2 == 0).forEach(IntegerPrinter::print);
// 过滤,查找可能的无效值,这里返回Optional,表示有可能找到了,也有可能没找到,要对invalidAge做进一步的处理和判断才能知道
Optional<Integer> invalidAge = numbers.stream().filter(n -> n < 0 || n > 100).findAny();
System.out.println(invalidAge.isPresent() ? invalidAge.get(): "未找到");
boolean num4Exists = numbers.stream().anyMatch(n -> n == 4);
System.out.println("4是否存在:" + num4Exists);
}
private static class IntegerPrinter {
public static void print(Integer n) {
System.out.println(n);
}
}
}
前面的几行代码都很简单,掌握了lambda表达式和方法引用的情况下,这些都很容易理解,Optional这个类我们再介绍一下。
JDK8中的java.util.Optional,你可以理解它是一个用来存放数据的容器,它的用法还是挺多的,涉及到很多东西,此处我们先简单介绍,看下面的代码:
Integer age = service.getUserAge();
if (age == null) {
System.out.println("此用户没有填写自己的年龄");
} else {
System.out.println("此用户的年龄是" + age + "岁");
}
这样的代码在具体业务中是很常见的,甚至可以说是写的非常之多。下面我们用Optional类改造这段代码:
Optional<Integer> age = service.getUserAge();
int ageValue = age.orElseThrow(() -> new IllegalArgumentException("此用户没有填写自己的年龄"));
在这段代码中,第二行代码执行时,如果用户的年龄不存在,就会抛出异常,否则会有一个有效的值赋给ageValue这个变量,想想传统的判断没有值时抛出的异常是怎么写的?是不是简化了很多?
再举一例:
Optional<Integer> age = service.getUserAge();
int ageValue = age.orElse(-1);
许多时候我们也用-1表示用户没有填写自己的年龄这样的业务逻辑来表示数据,那么此时就不必再判断用户年龄是否有效,无效时再赋-1的值这样的操作了。
收集结果
上面的例子,我们是对数据进行了遍历、过滤和查找,但许多时候,我们是要将符合条件的数据找出来以作它用的,这个时候怎么办呢?
package com.wasu.t.stream;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
/**
* 使用流进行数据收集
*
* @author lidawei
* @date 2021/8/12 18:22
*/
public class Jdk8StreamDemo6 {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
List<Integer> odds = numbers.stream().filter(n -> n % 2 != 0).collect(Collectors.toList());
for (Integer odd : odds) {
System.out.println(odd);
}
}
private static class IntegerPrinter {
public static void print(Integer n) {
System.out.println(n);
}
}
}
上述代码,会将numbers列表中的所有奇数都找出来,然后放到odds这个列表中。collect也是Stream中的方法,它接受一个函数式接口,而Collectors.toList()满足了这样的条件,作用就是将通过流传递过来的数据收集起来,放到一个新的列表中去。
聚合操作
package com.wasu.t.stream;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
/**
* 流的聚合操作
*
* @author lidawei
* @date 2021/8/12 18:22
*/
public class Jdk8StreamDemo7 {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
// 求最小值
Optional<Integer> min = numbers.stream().min(Integer::compareTo);
// 求最大值
Optional<Integer> max = numbers.stream().max(Integer::compareTo);
// 总共有多少个元素
long count = numbers.stream().count();
// 总共有多少个奇数
long oddsCount = numbers.stream().filter(n -> n % 2 != 0).count();
}
}
映射(map方法)
这个从根本上讲,就是对数据进行二次加工。
package com.wasu.t.stream;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
/**
* 使用流的map方法对数据二次加工
*
* @author lidawei
* @date 2021/8/21 16:53
*/
public class Jdk8StreamDemo8 {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
List<Integer> list = numbers.stream().map(e -> e * 2).collect(Collectors.toList());
list.stream().forEach(IntegerPrinter::print);
}
private static class IntegerPrinter {
public static void print(Integer n) {
System.out.println(n);
}
}
}
map方法的核心思想是:它接受一个java.util.function.Function这样的函数式接口,这个函数式接口的模式是收到一个值,然后再返回一个值,map方法的逻辑是逐个将流中的元素放到java.util.function.Function接口中去,那么,代码List<Integer> list = numbers.stream().map(e -> e * 2).collect(Collectors.toList());的逻辑就是将流中的数字逐个传给java.util.function.Function接口,再将这个接口的返回值收集起来,放到list中去,所以,上述代码输出如下:
2
4
6
8
10
过程计算(Map-Reduce)
Map-Reduce是一个略微复杂的东西,我们先从最简单的代码入手:
package com.wasu.t.stream;
import java.util.stream.Stream;
/**
* 使用流的reduce进行计算
*
* @author lidawei
* @date 2021/8/21 16:53
*/
public class Jdk8StreamDemo9 {
public static void main(String[] args) {
// 累加求和,得到15
Integer sum = Stream.of(1, 2, 3, 4, 5).reduce(0, (n1, n2) -> n1 + n2);
System.out.println(sum);
// 自定义reduce过程,得到1
Integer integer = Stream.of(1, 2, 3, 4, 5).reduce(0, (n1, n2) -> (n1 + n2) % 2);
System.out.println(integer);
}
}
第一个累加求和的过程计算,这个很简单,以0为基数:
- 第一次reduce,传入基数0和第一个数字1,得到1
- 第二次reduce,传入前一次的结果1和第二个数字2,得到3
- 第三次reduce,传入前一次的结果3和第三个数字3,得到6
- 第四次reduce,传入前一次的结果6和第四个数字4,得到10
- 第五次reduce,传入前一次的结果10和第五个数字5,得到15
- 没有第六个数字了,至此结束。
第二个自定义计算过程,会得到1,为什么呢?以0为基数:
- 第一次reduce,传入基数0和第一个数字1,(0+1)%2得到1
- 第二次reduce,传入前一次的结果1和第二个数字2,(1+2)/2得到1
- 第三次reduce,传入前一次的结果1和第三个数字3,(1+3)%2得到0
- 第四次reduce,传入前一次的结果0和第四个数字4,(0+4)%2得到0
- 第五次reduce,传入前一次的结果0和第五个数字5,(0+5)%2得到1
- 没有第六个数字了,至此结束。
💡基数,就是从开始要计算的时候,就拿着这个数字去。
为了验证我们的逻辑,我们改造一个这个代码:
package com.wasu.t.stream;
import java.util.stream.Stream;
/**
* 使用流的reduce进行计算
*
* @author lidawei
* @date 2021/8/21 16:53
*/
public class Jdk8StreamDemo10 {
public static void main(String[] args) {
// 下面的reduce过程会得到1
Integer integer = Stream.of(1, 2, 3, 4, 5).reduce(0, (n1, n2) -> {
Integer val = (n1 + n2) % 2;
System.out.printf("(%d + %d) %%2 == %d\n", n1, n2, val);
return val;
});
System.out.println(integer);
}
}
运行得到以下输出:
(0 + 1) %2 == 1
(1 + 2) %2 == 1
(1 + 3) %2 == 0
(0 + 4) %2 == 0
(0 + 5) %2 == 1
1
相信你现在已经知道reduce的计算过程原理了。
并行流
并行流实践中用的并不是非常多,主要原因有两点:
- 当数据量较多时,我们通常要进行数据的拆分和业务逻辑的重组,在内存中进行并发计算的场景并不多,因为虽然在内存中可以这以做提升效率了,但是事实上当用户量比较大数据量比较大请求量也比较大的时候,是根本撑不住的
- Java应用程序占用内存挺多的,不到万不得已,不要将大量数据放到内存中进行直接计算
重要提示:并行流是在多个线程中并行执行的,所以,如果编写并行流的代码,一定要注意线程安全问题。
这些都是经验总结。所以,并行流的应用,我们回头再研究,有兴趣的同学可先自行研究学习。
接口默认方法和静态方法
接口的默认方法
在JDK8之前,在接口中只能声明一个接口,不能带有任何实现。在这种情况下,如果要写一个抽象方法让这个接口的各个子类使用,就只能先写一个抽象类实现这个接口,再让各子类继承这个抽象类,于是各个子类的继承机制就被限制住了,不够灵活(因为Java中只允许单继承)。在接口中声明默认方法,就很好的解决了这个问题,各个子类实现了这个接口之后,还可以自己有自己的继承机制。
package com.wasu.t.intf;
/**
* 接口的默认方法示例
*
* @author lidawei
* @date 2022/8/22 9:15
*/
public class InterfaceDefaultMethodDemo {
public static void main(String[] args) {
Publisher p1 = new A();
p1.print();
p1.serial();
Publisher p2 = new B();
p2.print();
p2.serial();
}
}
interface Publisher {
void print();
default void serial() {
System.out.println("serial number is null");
}
}
class A implements Publisher {
@Override
public void print() {
System.out.println("class A print method");
}
}
class B implements Publisher {
@Override
public void print() {
System.out.println("class B print method");
}
@Override
public void serial() {
System.out.println("class B serial number");
}
}
执行上述代码,得到以下输出:
class A print method
serial number is null
class B print method
class B serial number
结论很明确:
- 如果子类实现了接口中的默认方法,那么该接口中的默认方法就会被覆盖
- 如果子类中没有实现接口中的默认方法,那么该接口中的默认方法就会在子类中可用
接口的静态方法
在JDK8之前,接口是同样是不允许有静态方法的,现在我们也可以这样定义了,代码如下:
package com.wasu.t.intf;
/**
* 接口的静态方法示例
*
* @author lidawei
* @date 2022/8/22 9:15
*/
public class InterfaceStaticMethodDemo {
public static void main(String[] args) {
Movable p1 = new MA();
p1.print();
Movable.serial();
// 下面这行代码会报错
// MB.serial();
Movable p2 = new MB();
p2.print();
Movable.serial();
MB.serial();
}
}
interface Movable {
void print();
static void serial() {
System.out.println("serial number is null");
}
}
class MA implements Movable {
@Override
public void print() {
System.out.println("class A print method");
}
}
class MB implements Movable {
@Override
public void print() {
System.out.println("class B print method");
}
public static void serial() {
System.out.println("class B serial number");
}
}
运行上述代码,得到如下输出:
class A print method
serial number is null
class B print method
serial number is null
class B serial number
结论很明确:
- 实现了接口的子类,可以直接覆盖接口中的静态方法
- 不能通过
实例名.接口静态方法的方式调用该静态方法
- 如果子类覆盖了接口中的静态方法,就可以通过
子类名.静态方法的方式调用该静态接口
- 如果子类没有覆盖接口中的静态方法,就只能通过
接口名.静态方法的方式调用该静态接口
新时间日期API
JDK8提供了一套全新的日期时间,非常好用,它们都位于 java.time 包中,下面是一些关键类:
- Instant:代表的是时间戳
- LocalDate:不包含具体时间的日期
- LocalTime:不含日期的时间
- LocalDateTime:包含了日期及时间
常见用法
看这些代码,就能立即领会它们的使用方法了:
LocalDate nowDate = LocalDate.now();
//今天的日期:2018-09-06
System.out.println("今天的日期:" + nowDate);
//年:一般用这个方法获取年
int year = nowDate.getYear();
//year:2018
System.out.println("year:" + year);
//月:一般用这个方法获取月
int month = nowDate.getMonthValue();
//month:9
System.out.println("month:" + month);
//日:当月的第几天,一般用这个方法获取日
int day = nowDate.getDayOfMonth();
//day:6
System.out.println("day:" + day);
int dayOfYear = nowDate.getDayOfYear();//日:当年的第几天
System.out.println("dayOfYear:" + dayOfYear);//dayOfYear:249
//星期
System.out.println(nowDate.getDayOfWeek());//THURSDAY
System.out.println(nowDate.getDayOfWeek().getValue());//4
//月份
System.out.println(nowDate.getMonth());//SEPTEMBER
System.out.println(nowDate.getMonth().getValue());//9
LocalDateTime nowDateTime = LocalDateTime.now();
System.out.println("今天是:" + nowDateTime);//今天是:2018-09-06T15:33:56.750
System.out.println(nowDateTime.getYear());//年
System.out.println(nowDateTime.getMonthValue());//月
System.out.println(nowDateTime.getDayOfMonth());//日
System.out.println(nowDateTime.getHour());//时
System.out.println(nowDateTime.getMinute());//分
System.out.println(nowDateTime.getSecond());//秒
System.out.println(nowDateTime.getNano());//纳秒
//日:当年的第几天
System.out.println("dayOfYear:" + nowDateTime.getDayOfYear());//dayOfYear:249
//星期
System.out.println(nowDateTime.getDayOfWeek());//THURSDAY
System.out.println(nowDateTime.getDayOfWeek().getValue());//4
//月份
System.out.println(nowDateTime.getMonth());//SEPTEMBER
System.out.println(nowDateTime.getMonth().getValue());//9
LocalTime相对于LocalData来说几乎提供了同样的API,使用也很简单。
我们在这里再列举几个实践中非常常见的应用场景:
计算时间差
LocalDate startDate = LocalDate.of(1993, Month.OCTOBER, 19);
System.out.println("开始时间 : " + startDate);
LocalDate endDate = LocalDate.of(2017, Month.JUNE, 16);
System.out.println("结束时间 : " + endDate);
long daysDiff = ChronoUnit.DAYS.between(startDate, endDate);
System.out.println("两天之间的差在天数 : " + daysDiff);
Instant inst1 = Instant.now();
Instant inst2 = inst1.plus(Duration.ofSeconds(10));
System.out.println("Difference : " + Duration.between(inst1, inst2));
Instant inst3 = inst1.plus(Duration.ofSeconds(100));
System.out.println("Difference : " + Duration.between(inst1, inst3));
System.out.println("Difference in milliseconds : " + Duration.between(inst1, inst2).toMillis());
时间增减
//三天后
LocalDate afterThreeDays = LocalDate.now().plusDays(3);
//三天前
LocalDate threeDaysAgo = LocalDate.now().minusDays(3);
时区信息
// 无时区信息的时间
Instant instant = Instant.now();
System.out.println(instant);
// 获取当前时区的时间
System.out.println(instant.atZone(ZoneId.systemDefault()));
获取时间戳
// 当前时间戳:单位为秒
System.out.println(instant.getEpochSecond());
// 当前时间戳:单位为毫秒
System.out.println(instant.toEpochMilli());
判断闰年
// 判断是否为闰年
bool isLeapYear = today.getYear() + " is leap year:" + LocalDate.now().isLeapYear();
System.out.println(isLeapYear);
日期时间格式化
LocalDate localDate = LocalDate.now();
// 使用几个内置的格式
System.out.println("ISO_DATE: " + localDate.format(DateTimeFormatter.ISO_DATE));
System.out.println("BASIC_ISO_DATE: " + localDate.format(DateTimeFormatter.BASIC_ISO_DATE));
System.out.println("ISO_WEEK_DATE: " + localDate.format(DateTimeFormatter.ISO_WEEK_DATE));
System.out.println("ISO_ORDINAL_DATE: " + localDate.format(DateTimeFormatter.ISO_ORDINAL_DATE));
LocalTime localTime = LocalTime.now();
System.out.println(localTime);
System.out.println("ISO_TIME: " + localTime.format(DateTimeFormatter.ISO_TIME));
System.out.println("HH:mm:ss: " + localTime.format(DateTimeFormatter.ofPattern("HH:mm:ss")));
// 自己定义格式
System.out.println("yyyy/MM/dd: " + localDate.format(DateTimeFormatter.ofPattern("yyyy/MM/dd")));
重复注解与类型注解
重复注解
在原来的注解的基础上,我们来探讨一下。
在我们自己定义的注解类上添加@Repeatable这个JDK8提供的注解,就可以使得自己的这个注解在一个类上使用多次。这就是重复注解。
重复注解我在实践中还没有用过,以后再研究吧。
类型注解
虽然注解在JDK5中就有了,但是在JDK8之前,注解只能放在类、方法、属性中声明,在JDK8中,已经可以在任何地方声明注解了,例如:
// 实例化类
new @Interned MyClass();
// 类型映射
myString = (@NonNull String) str;
// 在implements语句中应用
class UnmodifiableList<T> implements @Readonly List<@Readonly T> {
}
// 定义方法monitorTemperature时,声明要抛出异常,可以使用类型注解
void monitorTemperature() throws @Critical TemperatureException {
}
Tips:Java代码编译成字节码之后,并不包含类型注解,所以,它仅仅是辅助我们开发人员的一种工具,不是Java语义定义的内容,平时用的也不多,知道一下就行了。
BASE64编码解码
JDK8中已经内置了对Base64编码解码的支持,不必再依赖第三方库了,请看下面的代码:
package com.wasu.t.base64;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
/**
* JDK8的Base64编码解码
* @author lidawei
* @date 2022/8/22 11:46
*/
public class Base64Demo {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "Java教程";
String s3 = "Java大法好👍";
byte[] bytes1 = Base64.getEncoder().encode(s1.getBytes(StandardCharsets.UTF_8));
byte[] bytes2 = Base64.getEncoder().encode(s2.getBytes(StandardCharsets.UTF_8));
byte[] bytes3 = Base64.getEncoder().encode(s3.getBytes(StandardCharsets.UTF_8));
String ss1 = new String(Base64.getDecoder().decode(bytes1));
String ss2 = new String(Base64.getDecoder().decode(bytes2));
String ss3 = new String(Base64.getDecoder().decode(bytes3));
System.out.println(s1.equals(ss1));
System.out.println(s2.equals(ss2));
System.out.println(s3.equals(ss3));
}
}
上述代码会输出三个true,逻辑也很简单,把一个字符串编码之后再解码,它一定和之前的值是完全相等的,包括中文和emoji表情符号也能解析。
Optional类
Optional初见
JDK8中新增了一个成员 java.util.Optional,这个类非常好用。我们先看下面的传统型代码:
package com.wasu.t.opt;
import java.util.Optional;
/**
* JDK8的Optional类用法示例
*
* @author lidawei
* @date 2022/8/23 21:50
*/
public class OptionalDemo01 {
private static class User {
String name;
}
public static String getUserName(User user) {
// 传统的写法
if (user == null) {
return "unknown";
} else {
return user.name;
}
}
public static String getUserName2(User user) {
// 引入Optional类的写法
return Optional.ofNullable(user).orElse(new User()).name;
}
}
看看getUserName方法中的传统的写法,在以前的业务代码中,我们大量书写这种代码,再看看新式的getUserName2方法中的写法,代码明显简洁了很多,我们再来一个示例代码看一下:
package com.wasu.t.opt;
import java.util.Optional;
/**
* JDK8的Optional类用法示例
*
* @author lidawei
* @date 2022/8/23 21:50
*/
public class OptionalDemo02 {
private static class User {
private String name;
public String getName() {
return name;
}
}
/**
* 获取用户名称
* @param user 用户信息,不允许为空
* @return 返回用户名称,如果不存在,使用-代替
* @throws IllegalAccessException 用户为空时抛出异常
*/
public static String getUserName(User user) throws IllegalAccessException {
if (user == null) {
throw new IllegalAccessException("用户不允许为空");
} else if (user.name != null) {
return user.name;
} else {
return "-";
}
}
/**
* 获取用户名称
* @param user 用户信息,不允许为空
* @return 返回用户名称,如果不存在,使用-代替
* @throws IllegalAccessException 用户为空时抛出异常
*/
public static String getUserName2(User user) throws IllegalAccessException {
// 引入Optional类的写法
return Optional.ofNullable(Optional.ofNullable(user).orElseThrow(() -> new IllegalAccessException("用户不允许为空")).name).orElse("-");
}
}
去研究JDK8中Optional的源代码,就会发现,它其实是一个容器,里面存放我们需要用到的数据,然后帮助我们做了许多的判断和优化,使得代码更加简洁和优雅。
创建Optional实例
// t不能为空
Optional.of(T t);
// 创建一个空的Optional实例
Optional.empty();
// 若 t 不为 null,创建 Optional 实例,否则创建空实例
Optional.ofNullable(T t);
判断Optional中是否有数据
package com.wasu.t.opt;
import java.util.Optional;
/**
* 判断Optional中是否有数据
*
* @author lidawei
* @date 2022/8/23 22:04
*/
public class OptionalDemo03 {
public static void main(String[] args) {
Optional.ofNullable(null).ifPresent(s -> System.out.println("有值1"));
Optional.of("s").ifPresent(s -> System.out.println("有值2"));
}
}
上述代码会输出有值2。因为第一个ifPresent判断发现Optional中没有数据,所以不会调用它的Consumer,第二个ifPresent发现Optional中有数据,所以会调用它的Consumer。
获取值
当我们从一个变量中获取值的时候,通常要考虑它是否为空,比如这个数据是从数据库中查出来的,那么它极有可能为空(比如用户的住址,很有可能用户当初没有填写),那么就很有必要做一些判断和处理了,通常我们就是这样写的代码:
public String getUserAddress(String userId) {
if (userId == null) {
throw new IllegalArgumentException("请求参数无效");
}
User user = service.getUserFromMySql(userId);
if (user == null) {
throw new IllegalAccessException("用户不存在");
}
String address = user.getAddress();
if (address == null) {
return "未知";
} else {
return address;
}
}
讲真,真是又臭又长,可也没什么办法,这种代码我们写了无数遍,没有Optional类的时候,我们还要接着写。现在,我们用Optional类改造这个代码,注意,适度改造就可以了,也不要太狠了反倒不易于阅读和理解。
public String getUserAddress(String userId) {
if (userId == null) {
throw new IllegalArgumentException("请求参数无效");
}
User user = Optional.ofNullable(service.getUserFromMySql(userId)).orElseThrow(() -> new IllegalAccessException("用户不存在"));
return Optional.ofNullable(user.getAddress()).orElse("未知");
}
👉👉👉Tips:上述代码可以Optional套Optional以实现一行代码搞完所有逻辑,但是反倒不易于理解,所以,差不多就行了。
防止抛出异常
对于上述代码,我们有可能不希望它抛出那么些异常,那么我们继续改造它:
package com.wasu.t.opt;
import java.util.Optional;
import java.util.Random;
/**
* 使用Optional实现优雅的逻辑判断,防止抛出异常
*
* @author lidawei
* @date 2022/8/23 22:04
*/
public class OptionalDemo04 {
private static UserService service = new UserService();
public static void main(String[] args) {
String address1 = OptionalDemo04.getUserAddress("1");
System.out.println("address1: " + address1);
String address2 = OptionalDemo04.getUserAddress(null);
System.out.println("address2: " + address2);
}
private static class User {
private String address;
public String getAddress() {
return address;
}
}
private static class UserService {
public User getUserFromMySql(String userId) {
if (new Random().nextBoolean()) {
return new User();
} else {
return null;
}
}
}
public static String getUserAddress(String userId) {
if (userId == null) {
return "未知";
}
User u = Optional.ofNullable(service.getUserFromMySql(userId)).orElseGet(User::new);
return Optional.ofNullable(u.getAddress()).orElse("未知");
}
}
上述代码可以实现的结果:
- userId为空时不抛出异常
- 依据userId得到user,user为空时不抛出异常
- 依据user获得address,address为空时不抛出异常
- 所有不抛出异常的地方都设置默认值直接返回
Tips: 在需要抛出异常的地方才抛出,不需要的时候,简洁优雅的代码是非常好的。
